
Построение эффективных AI-агентов
Построение эффективных агентов
Опубликовано 19 декабря 2024
Мы работали с десятками команд, создающих LLM-агентов в разных отраслях. Наиболее успешные реализации, как правило, используют простые, компонуемые паттерны, а не сложные фреймворки.
За последний год мы сотрудничали с десятками команд, разрабатывающих агентов на базе больших языковых моделей (LLM) в различных сферах. Наиболее успешные внедрения, как правило, не использовали сложные фреймворки или специализированные библиотеки. Вместо этого они строились на простых, компонуемых паттернах.
В этой статье мы делимся накопленным опытом работы с клиентами и собственными разработками агентов, а также даём практические рекомендации разработчикам по созданию эффективных агентов.
Что такое агенты?
Термин «агент» можно трактовать по-разному. Некоторые клиенты определяют агентов как полностью автономные системы, которые работают независимо длительное время, используя различные инструменты для решения сложных задач. Другие используют этот термин для более предписывающих реализаций, следующих заранее заданным сценариям. В Anthropic мы относим все эти варианты к агентным системам, но проводим важное архитектурное различие между workflow и agent:
- Workflow — это системы, в которых LLM и инструменты оркестрируются по заранее определённым путям кода.
- Agent — это системы, в которых LLM динамически управляет собственными процессами и использованием инструментов, контролируя, как именно выполняется задача.
Далее мы подробно рассмотрим оба типа агентных систем. В Приложении 1 («Агенты на практике») описаны два направления, где клиенты получили особую ценность от таких систем.
Когда стоит (и не стоит) использовать агентов
При создании приложений с LLM мы рекомендуем искать максимально простое решение и увеличивать сложность только по необходимости. Иногда это означает, что агентные системы вообще не нужны. Агентные системы часто жертвуют задержкой и стоимостью ради лучшего качества выполнения задач, и этот компромисс стоит учитывать.
Когда требуется большая сложность, workflow обеспечивают предсказуемость и стабильность для чётко определённых задач, а агенты лучше подходят для масштабируемых сценариев, где важна гибкость и принятие решений на основе модели. Однако для многих приложений достаточно оптимизации одиночных вызовов LLM с retrieval и in-context примерами.
Когда и как использовать фреймворки
Существует множество фреймворков, упрощающих реализацию агентных систем, среди них:
- Claude Agent SDK;
- Strands Agents SDK от AWS;
- Rivet — визуальный конструктор workflow для LLM с drag-and-drop интерфейсом;
- Vellum — ещё один GUI-инструмент для создания и тестирования сложных workflow.
Эти фреймворки позволяют быстро стартовать, упрощая стандартные низкоуровневые задачи: вызовы LLM, определение и парсинг инструментов, связывание вызовов. Однако они часто добавляют дополнительные уровни абстракции, которые могут скрывать реальные prompt-ы и ответы, усложняя отладку. Также возникает соблазн добавить лишнюю сложность там, где достаточно простого решения.
Мы советуем разработчикам начинать с прямого использования LLM API: многие паттерны реализуются в нескольких строках кода. Если вы используете фреймворк, убедитесь, что понимаете, как работает underlying code. Ошибочные предположения о «начинке» — частый источник ошибок у клиентов.
Смотрите наш cookbook для примеров реализации.
Базовые элементы, workflow и агенты
В этом разделе мы рассмотрим распространённые паттерны агентных систем, которые встречаются в продакшене. Начнём с базового строительного блока — дополненного LLM — и поэтапно увеличим сложность: от простых workflow до автономных агентов.
Базовый элемент: дополненный LLM
Основой агентных систем является LLM, расширенный такими возможностями, как retrieval, инструменты и память. Современные модели могут активно использовать эти возможности — генерировать поисковые запросы, выбирать подходящие инструменты, определять, какую информацию сохранить.
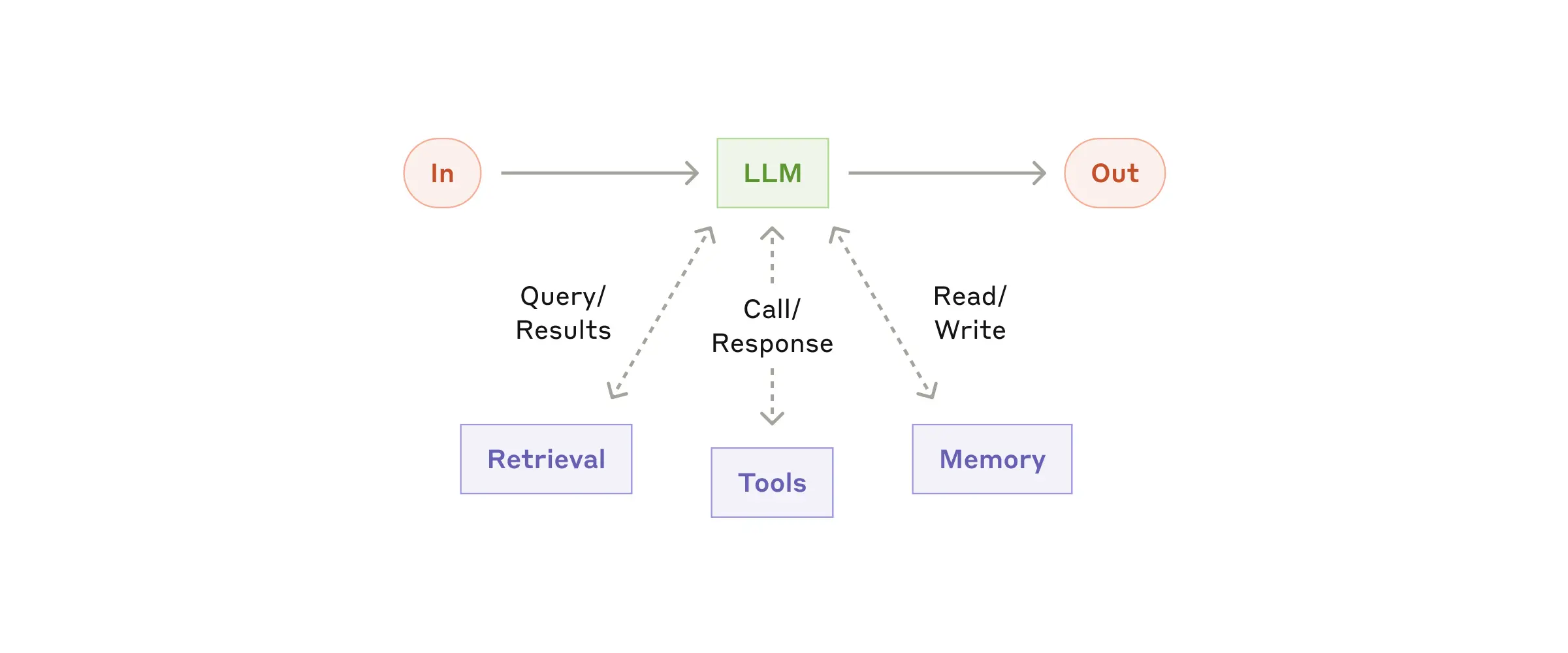
Рекомендуем сосредоточиться на двух ключевых аспектах: адаптации этих возможностей под ваш кейс и предоставлении удобного, хорошо документированного интерфейса для LLM. Существует множество способов реализации таких расширений, один из них — недавно представленный Model Context Protocol, который позволяет интегрировать сторонние инструменты через простой клиент.
Далее по тексту будем считать, что каждый вызов LLM обладает этими расширенными возможностями.
Workflow: цепочка prompt-ов
Цепочка prompt-ов разбивает задачу на последовательность шагов, где каждый вызов LLM обрабатывает результат предыдущего. На любом промежуточном этапе можно добавить программные проверки (см. «gate» на схеме ниже), чтобы убедиться, что процесс идёт по плану.
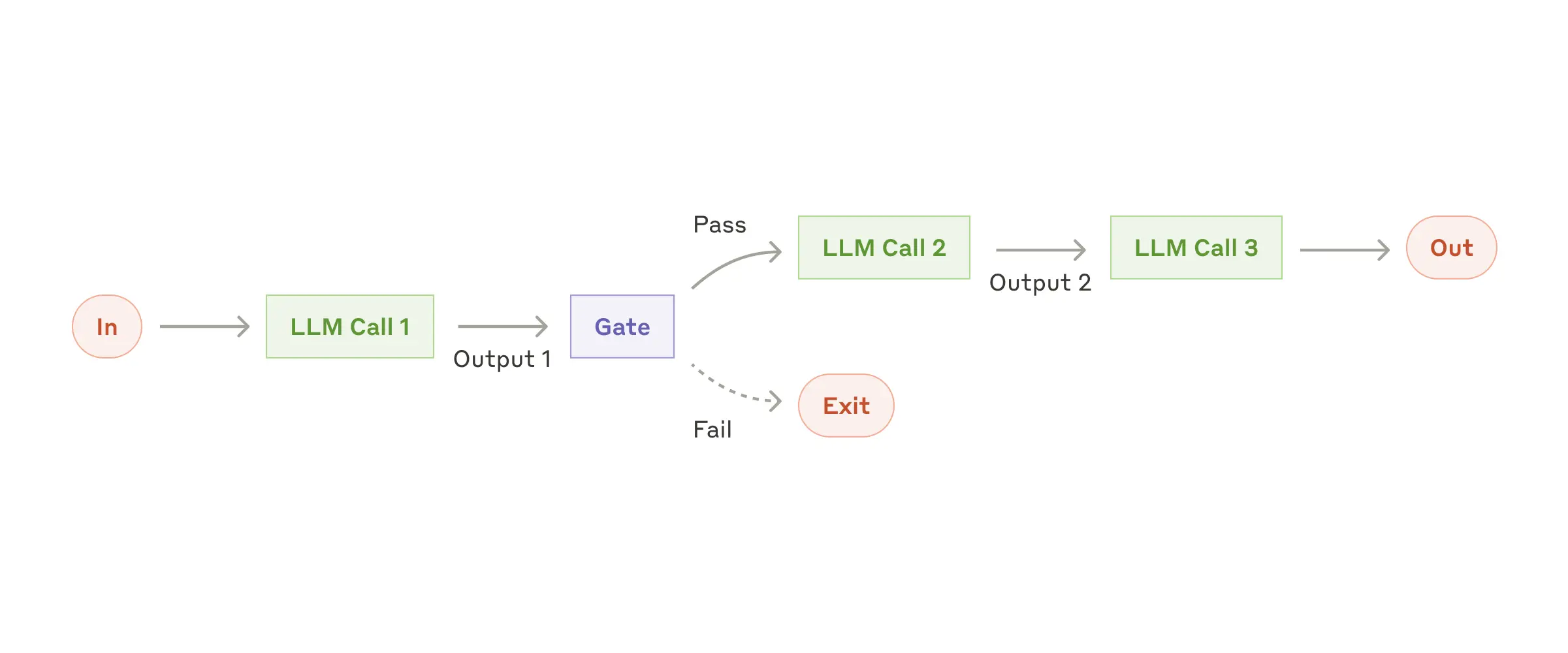
Когда использовать этот workflow: Подходит для задач, которые легко разбить на фиксированные подзадачи. Главная цель — обменять задержку на точность, делая каждый вызов LLM более простым.
Примеры применения цепочки prompt-ов:
- Генерация маркетингового текста с последующим переводом на другой язык.
- Создание структуры документа, проверка структуры по критериям, затем написание текста по структуре.
Workflow: маршрутизация
Маршрутизация классифицирует входные данные и направляет их на специализированную задачу. Такой workflow позволяет разделить ответственность и строить более специализированные prompt-ы. Без этого подхода оптимизация под один тип входа может ухудшить работу с другими.
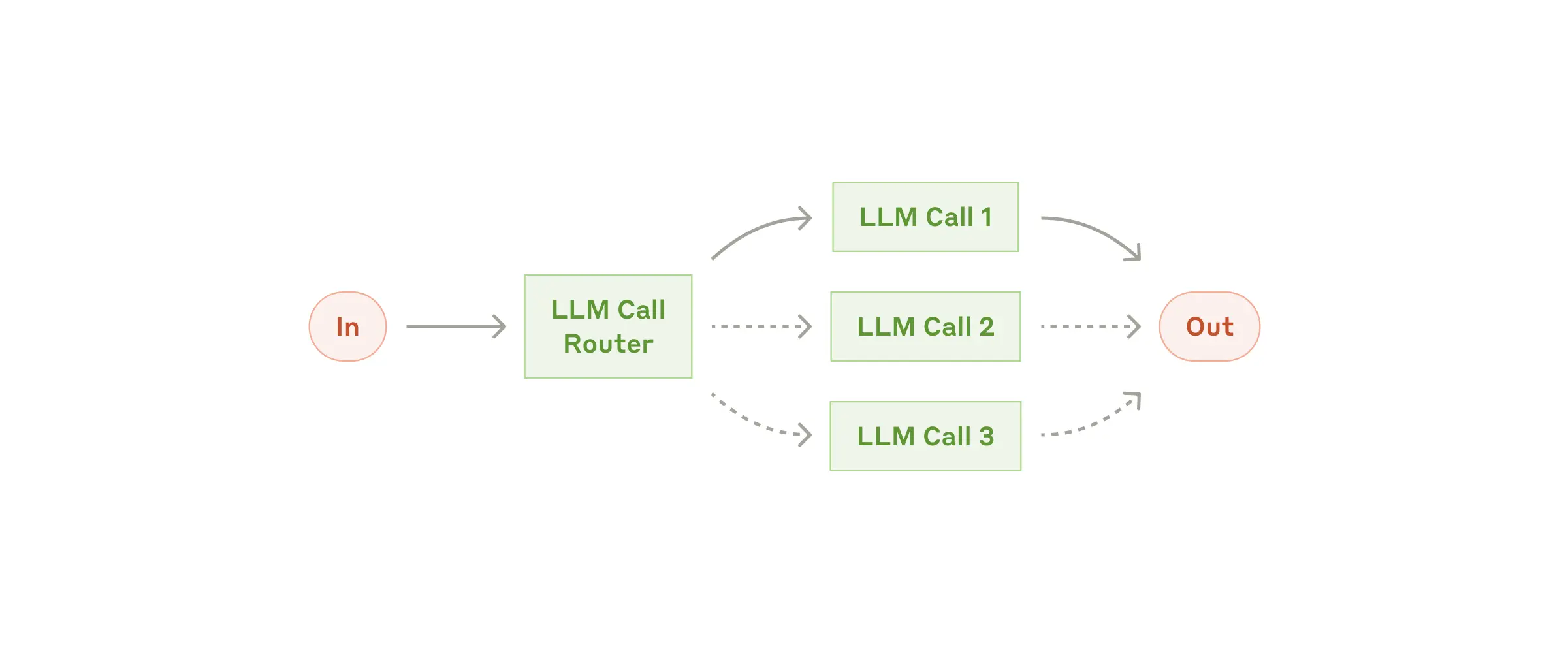
Когда использовать этот workflow: Подходит для сложных задач с чёткими категориями, которые лучше обрабатывать отдельно, и когда классификация может быть выполнена точно — либо LLM, либо классической моделью/алгоритмом.
Примеры применения маршрутизации:
- Распределение различных типов обращений в поддержку (общие вопросы, возвраты, техподдержка) по разным процессам, prompt-ам и инструментам.
- Маршрутизация простых/типовых вопросов на более дешёвые модели (например, Claude Haiku 4.5), а сложных — на более мощные (например, Claude Sonnet 4.5) для оптимизации качества.
Workflow: параллелизация
LLM могут выполнять задачи параллельно, а их результаты агрегируются программно. Такой workflow реализуется в двух вариантах:
- Секционирование: задача разбивается на независимые подзадачи, которые выполняются параллельно.
- Голосование: одна и та же задача решается несколько раз для получения разных вариантов.
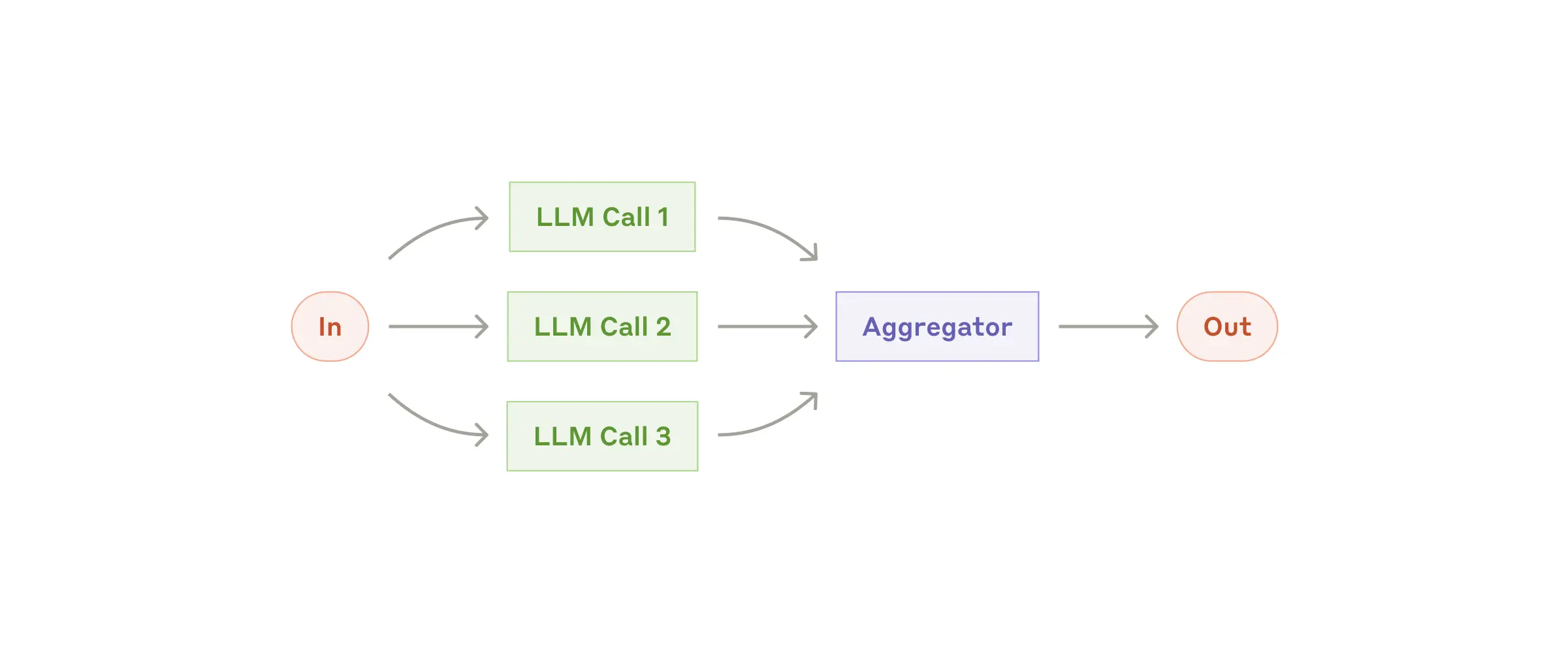
Когда использовать этот workflow: Эффективен, если подзадачи можно параллелить ради скорости или если нужны разные точки зрения/попытки для повышения надёжности результата. Для сложных задач с несколькими аспектами LLM обычно работают лучше, если каждый аспект обрабатывается отдельным вызовом.
Примеры применения параллелизации:
- Секционирование:
- Реализация guardrails: одна модель обрабатывает запрос пользователя, другая — фильтрует на неуместный контент. Это эффективнее, чем совмещать обе задачи в одном вызове.
- Автоматизация evals для оценки LLM: каждый вызов оценивает отдельный аспект работы модели.
- Голосование:
- Проверка кода на уязвимости: несколько prompt-ов анализируют и помечают проблемные места.
- Оценка контента на неуместность: разные prompt-ы оценивают отдельные аспекты, можно использовать разные пороги голосования для баланса FP/FN.
Workflow: оркестратор-воркеры
В этом workflow центральный LLM динамически разбивает задачу, делегирует подзадачи воркерам (LLM) и собирает их результаты.
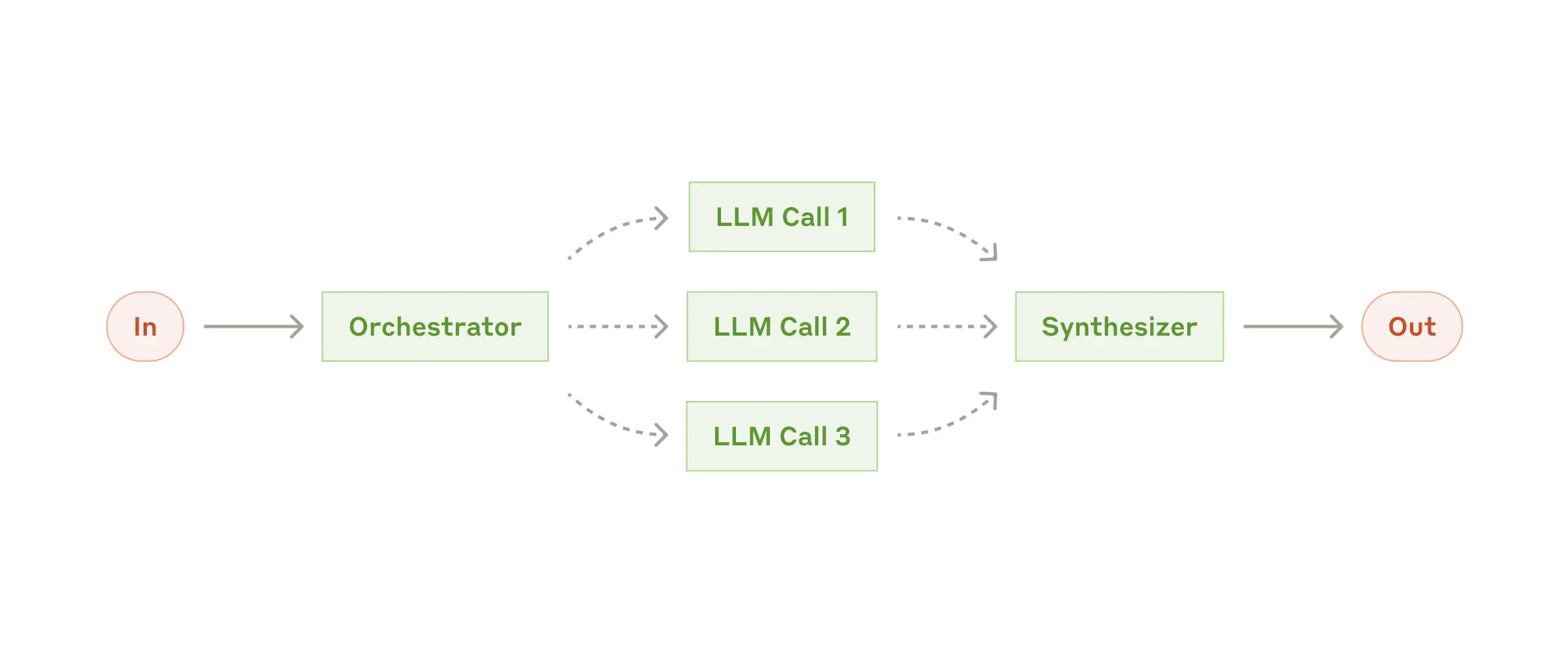
Когда использовать этот workflow: Подходит для сложных задач, где нельзя заранее определить подзадачи (например, при изменении кода количество файлов и характер изменений зависят от задачи). В отличие от параллелизации, здесь подзадачи определяются динамически оркестратором на основе входных данных.
Примеры применения оркестратор-воркеры:
- Продукты для кодирования, которые вносят сложные изменения в несколько файлов.
- Поисковые задачи, требующие сбора и анализа информации из разных источников.
Workflow: оценщик-оптимизатор
В этом workflow один вызов LLM генерирует ответ, а другой — оценивает и даёт обратную связь в цикле.
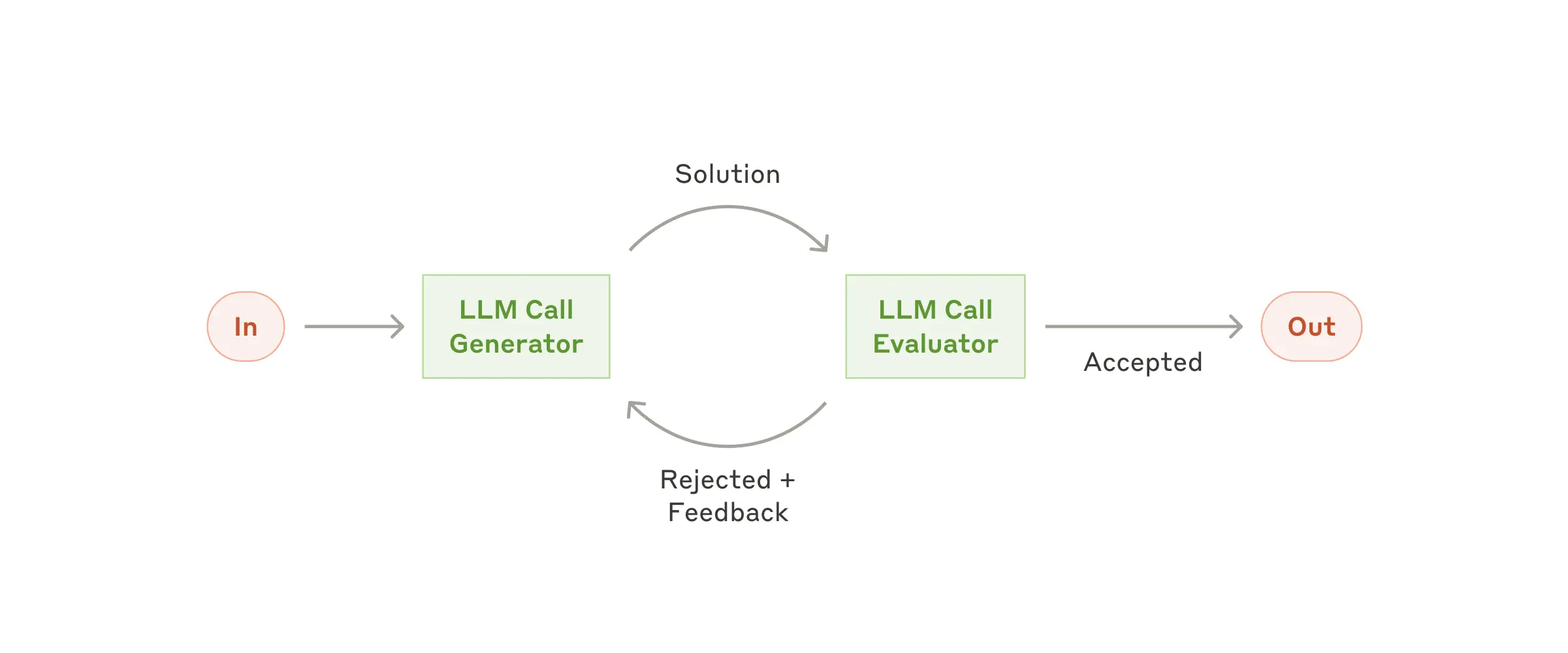
Когда использовать этот workflow: Особенно эффективен при наличии чётких критериев оценки и если итеративное улучшение даёт измеримый прирост качества. Два признака хорошей применимости: 1) ответы LLM реально улучшаются после человеческой обратной связи; 2) LLM способен сам давать такую обратную связь. Это похоже на итеративный процесс написания текста человеком.
Примеры применения оценщик-оптимизатор:
- Литературный перевод, где переводчик-LLM не всегда улавливает нюансы, а оценщик-LLM может дать полезную критику.
- Сложные поисковые задачи, требующие нескольких раундов поиска и анализа, где оценщик решает, нужны ли ещё итерации.
Агенты
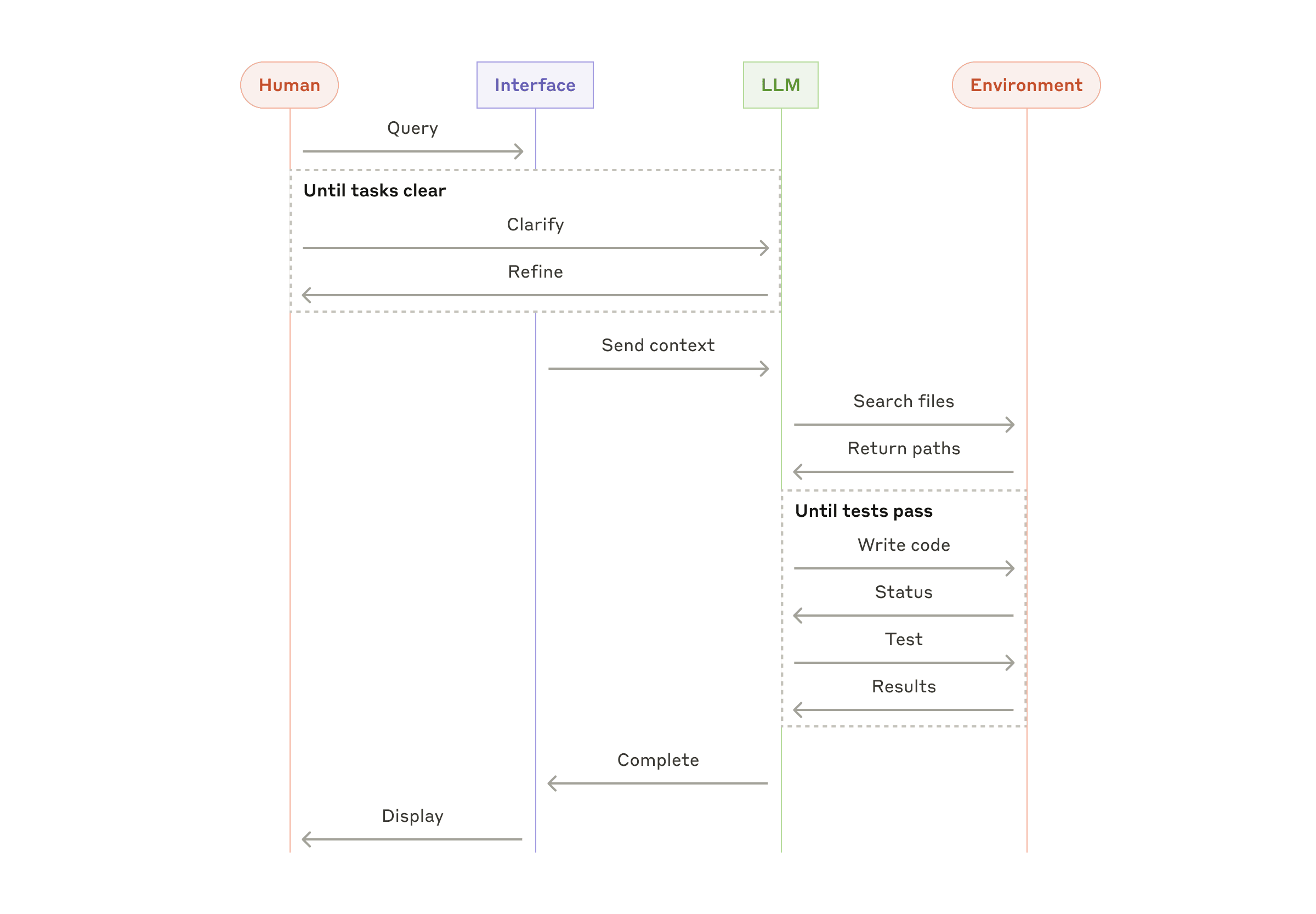
Агенты становятся всё более востребованными по мере развития LLM: они понимают сложные входные данные, умеют рассуждать, планировать, надёжно использовать инструменты и восстанавливаться после ошибок. Работа агента начинается с команды или диалога с человеком. После уточнения задачи агент планирует и действует автономно, при необходимости возвращаясь к пользователю за дополнительной информацией или решением. Важно, чтобы на каждом этапе агент получал «ground truth» из среды (например, результат вызова инструмента или выполнения кода) для оценки прогресса. Агент может запрашивать обратную связь у человека на контрольных точках или при блокировках. Обычно задача завершается по достижении цели, но часто добавляют условия остановки (например, максимум итераций) для контроля.
Агенты способны решать сложные задачи, но их реализация зачастую проста: это LLM, которые используют инструменты на основе обратной связи от среды в цикле. Поэтому критически важно тщательно проектировать набор инструментов и их документацию. Подробнее о best practices для инструментов — в Приложении 2 («Prompt Engineering для инструментов»).
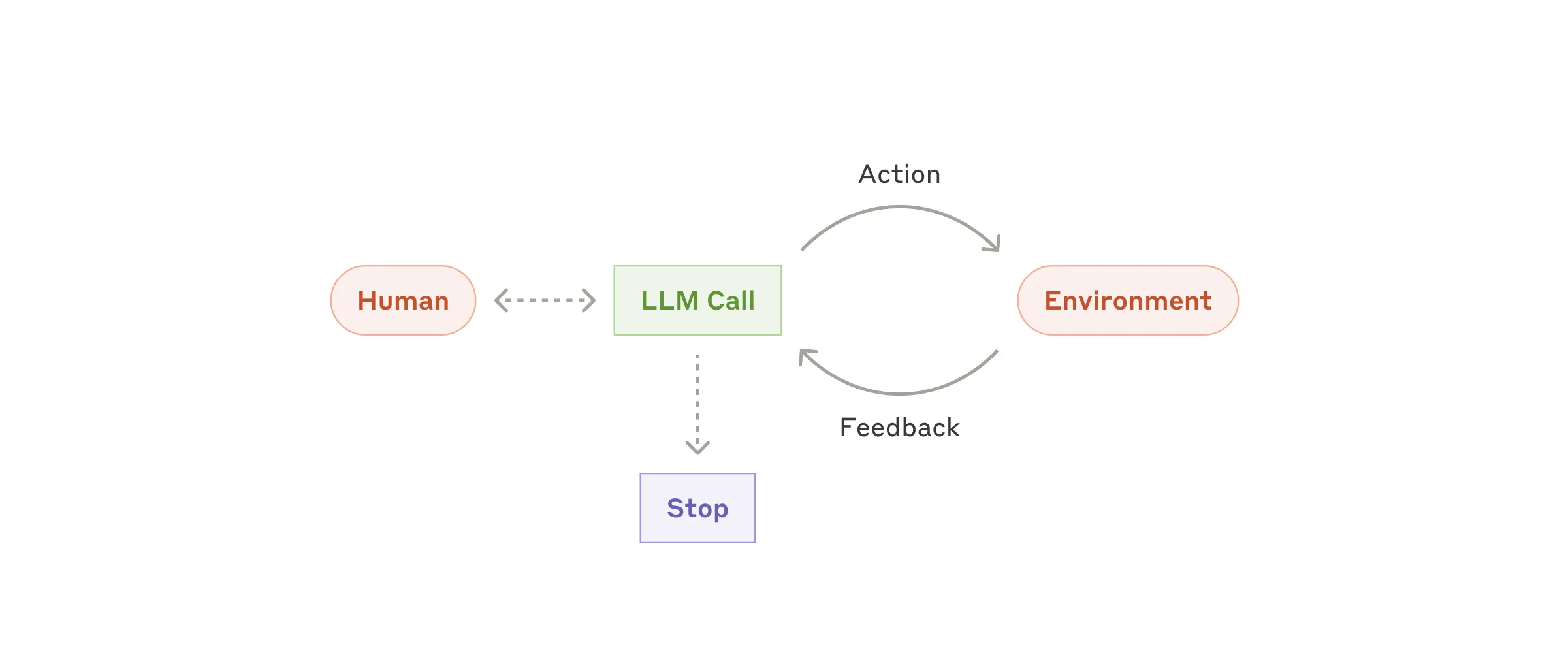
Когда использовать агентов: Для открытых задач, где невозможно заранее предсказать количество шагов и нельзя жёстко закодировать путь. LLM будет работать много раундов, и вам нужно доверять его решениям. Автономность агентов делает их идеальными для масштабирования задач в доверенных средах.
Автономность агентов означает большие расходы и риск накопления ошибок. Рекомендуем тщательно тестировать их в песочнице и использовать guardrails.
Примеры применения агентов:
Примеры из наших собственных реализаций:
- Кодирующий агент для решения SWE-bench задач, включающих правки множества файлов по описанию задачи;
- Наша референсная реализация «использования компьютера», где Claude выполняет задачи на компьютере.
Комбинирование и кастомизация паттернов
Эти строительные блоки — не догма, а распространённые паттерны, которые разработчики могут адаптировать и комбинировать под свои задачи. Ключ к успеху — измерять эффективность и итеративно улучшать реализацию. Повторим: добавляйте сложность только если это реально улучшает результат.
Итоги
Успех в работе с LLM — это не создание самой сложной системы, а построение правильной системы под ваши задачи. Начинайте с простых prompt-ов, оптимизируйте их с помощью тщательной оценки, и добавляйте многошаговые агентные системы только если простые решения не справляются.
При реализации агентов мы придерживаемся трёх принципов:
- Сохраняйте простоту в дизайне агента.
- Ставьте на первое место прозрачность, явно показывая шаги планирования агента.
- Тщательно прорабатывайте интерфейс агент-компьютер (ACI) через документацию и тестирование инструментов.
Фреймворки помогут быстро стартовать, но не бойтесь уменьшать уровень абстракции и строить на базовых компонентах по мере выхода в продакшен. Следуя этим принципам, вы сможете создавать агентов, которые не только мощные, но и надёжные, поддерживаемые и заслуживающие доверия пользователей.
Благодарности
Авторы: Эрик Шлунц и Барри Чжан. Эта работа основана на нашем опыте построения агентов в Anthropic и ценных инсайтах от наших клиентов, за что мы искренне благодарны.
Приложение 1: Агенты на практике
Работа с клиентами выявила два особенно перспективных применения AI-агентов, демонстрирующих практическую ценность описанных паттернов. Оба кейса показывают, что агенты приносят наибольшую пользу там, где задачи требуют и общения, и действий, имеют чёткие критерии успеха, поддерживают обратную связь и интеграцию с человеческим контролем.
A. Поддержка клиентов
Поддержка клиентов сочетает привычные чат-бот интерфейсы с расширенными возможностями через интеграцию инструментов. Это естественная область для более открытых агентов, потому что:
- Взаимодействия поддержки имеют диалоговую структуру, но требуют доступа к внешней информации и действиям;
- Можно интегрировать инструменты для получения данных клиента, истории заказов, статей базы знаний;
- Действия (например, возвраты или обновление тикетов) можно выполнять программно;
- Успех чётко измеряется пользовательскими метриками решения проблемы.
Ряд компаний подтвердили эффективность такого подхода, внедрив модели оплаты только за успешные решения, что говорит о доверии к своим агентам.
B. Кодирующие агенты
В области разработки ПО LLM-функционал быстро эволюционирует: от автодополнения кода до автономного решения задач. Агенты здесь особенно эффективны, потому что:
- Решения можно проверять автотестами;
- Агенты могут итеративно улучшать решения, используя результаты тестов как обратную связь;
- Проблемы чётко структурированы и формализованы;
- Качество результата можно объективно измерить.
В нашей реализации агенты уже решают реальные GitHub-issues в SWE-bench Verified только по описанию pull request. Однако, несмотря на автоматические тесты, человеческий review остаётся важным для соответствия решения архитектуре системы.
Приложение 2: Prompt engineering для инструментов
Какая бы агентная система ни строилась, инструменты почти всегда будут её важной частью. Инструменты позволяют Claude взаимодействовать с внешними сервисами и API, чётко определяя их структуру и описание в нашем API. В ответе Claude будет содержаться tool use block, если он планирует вызвать инструмент. Определения и спецификации инструментов требуют такого же внимания к prompt engineering, как и основные prompt-ы. В этом приложении мы расскажем, как делать prompt engineering для инструментов.
Обычно одну и ту же операцию можно описать по-разному. Например, редактирование файла — через diff или полную перезапись. Для структурированного вывода код можно возвращать в markdown или JSON. В программировании такие различия косметические и легко конвертируются, но некоторые форматы сложнее для LLM. Например, diff требует заранее знать, сколько строк изменяется, а код в JSON требует экранирования переносов строк и кавычек.
Наши рекомендации по выбору формата инструментов:
- Давайте модели достаточно токенов, чтобы «подумать» перед ответом.
- Держите формат максимально близким к тому, что модель встречала в интернете.
- Избегайте форматов с большим «накладным расходом» (например, точный подсчёт строк или экранирование кода).
Ориентируйтесь на то, сколько усилий вкладывается в human-computer interfaces (HCI), и уделяйте столько же внимания созданию качественных agent-computer interfaces (ACI). Вот несколько советов:
- Поставьте себя на место модели: очевидно ли, как использовать инструмент по описанию и параметрам? Если нет — скорее всего, и для модели это неочевидно. Хорошее определение инструмента включает примеры, edge cases, требования к формату и чёткие границы с другими инструментами.
- Меняйте имена параметров и описания, чтобы сделать их максимально понятными — как для джуниор-разработчика. Особенно важно при большом количестве похожих инструментов.
- Тестируйте, как модель использует инструменты: прогоняйте много примеров в workbench и итеративно улучшайте.
- Poka-yoke для инструментов: меняйте аргументы так, чтобы уменьшить вероятность ошибок.
В процессе создания агента для SWE-bench мы потратили больше времени на оптимизацию инструментов, чем на основной prompt. Например, модель ошибалась с относительными путями после смены директории, поэтому мы сделали обязательным использование абсолютных путей — и эта проблема исчезла.
Подпишитесь на рассылку для разработчиков
Обновления продуктов, инструкции, новости сообщества и многое другое — каждый месяц на ваш e-mail.