
Gemma 4: открытые AI-модели нового поколения для reasoning, агентных сценариев и локального запуска
Gemma 4: самые сильные открытые модели Google на сегодня
Если коротко: Google выпустила Gemma 4, и это, пожалуй, самое зрелое открытое семейство моделей компании на данный момент. Линейка заточена не только под диалог, но и под серьёзные задачи: сложное рассуждение, вызов инструментов, структурированный вывод, локальный запуск и агентные сценарии. Проще говоря, речь уже не о «ещё одной open model», а о платформе, на которой можно строить реальные AI-решения — от локальных помощников до продвинутых систем автоматизации.
Интерес к экосистеме Gemma, к слову, давно перестал быть нишевым. С момента выхода первого поколения модели семейства скачали более 400 миллионов раз, а сообщество собрало свыше 100 000 вариаций в Gemmaverse. Это уже не просто активность вокруг релиза — это живая инженерная среда, где модели дорабатывают, адаптируют и встраивают в прикладные продукты. И да, Gemma 4 распространяется по лицензии Apache 2.0, что для бизнеса и команд разработки значит очень много: меньше юридической нервотрёпки, больше свободы в развёртывании.
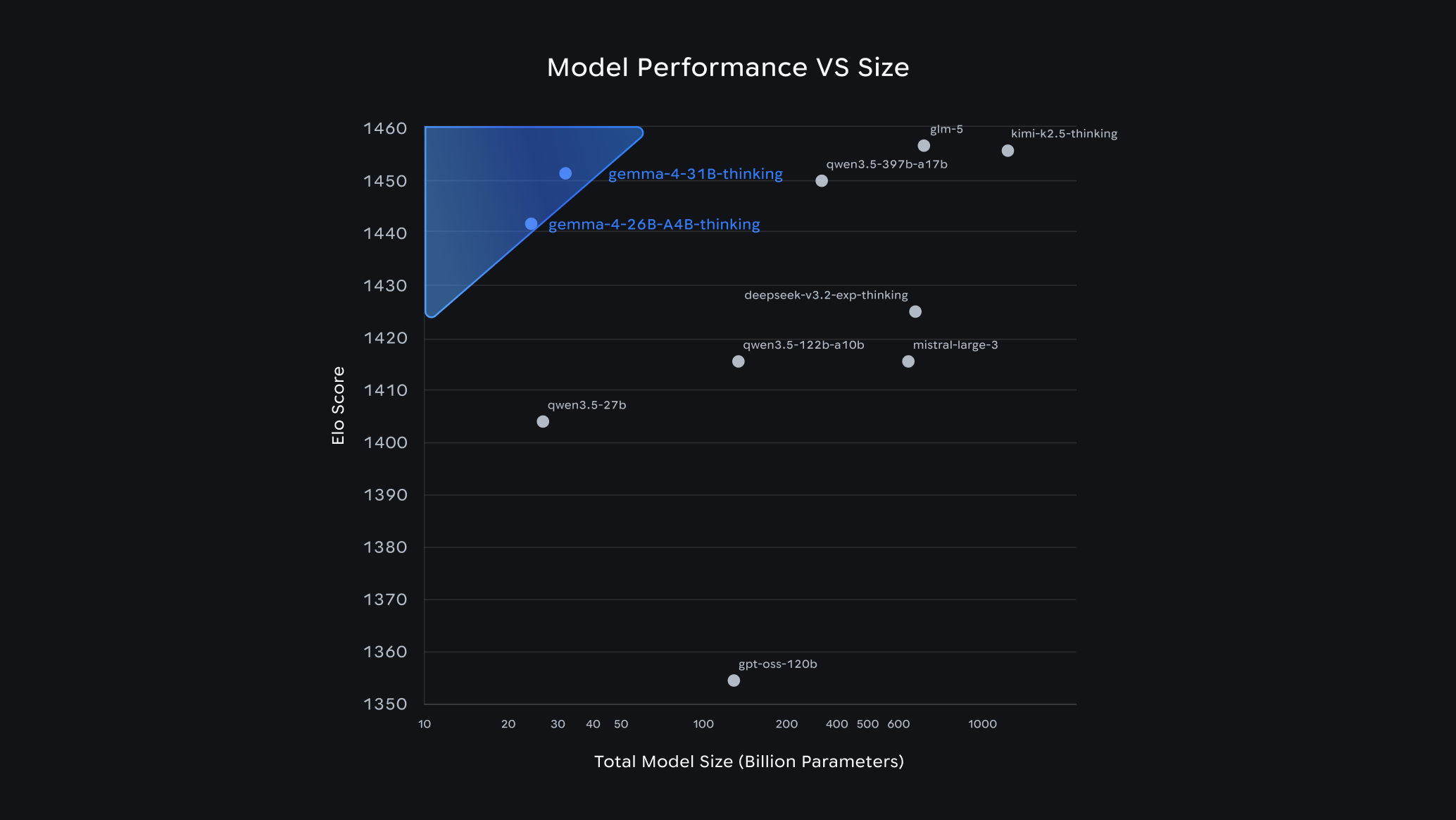
Сравнение производительности открытых моделей с учётом размера по данным Arena.ai на 1 апреля.
Gemma 4 опирается на те же фундаментальные исследования, что и семейство Gemini, но при этом ориентирована на открытость, гибкость и запуск на собственном оборудовании. Для компаний, которые смотрят в сторону разработки AI-агентов и автоматизации, это особенно любопытно: модель можно не просто протестировать в облаке, а встроить в свою инфраструктуру, дообучить под задачу и использовать в контролируемом контуре.
Что нового в Gemma 4 — и почему это важно
Google выпускает Gemma 4 в четырёх конфигурациях: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts и 31B Dense. Размеры разные, но идея одна: дать разработчикам выбор между компактностью, скоростью и максимальным качеством. Причём не на бумаге, а в реальных сценариях — от мобильных устройств до рабочих станций.
Старшие модели показывают очень сильные результаты для своего класса. 31B уже входит в число лидеров среди открытых моделей в рейтинге Arena AI, а 26B тоже держится в верхней группе. И вот тут начинается самое интересное: Gemma 4 обходит некоторые модели, которые заметно крупнее. Не в два раза. Сильно больше. Для инженерных команд это означает простую вещь: можно получить производительность уровня frontier без чудовищных требований к железу.
Именно поэтому линейка выглядит перспективно для корпоративных AI-сценариев, где важны не только метрики, но и экономика эксплуатации. Когда модель даёт высокий результат при умеренном размере, её проще внедрять в архитектуру AI-агентов, масштабировать и обслуживать. Без лишней магии, без кластера размером с полкомнаты.

Не только чат: reasoning, инструменты, код, мультимодальность
Gemma 4 создавалась не как модель «для поболтать». Её сильная сторона — многошаговое рассуждение, следование инструкциям и работа в агентных цепочках. Это важно, если вы строите не просто интерфейс с текстовым окном, а систему, которая должна планировать действия, обращаться к API, возвращать JSON, вызывать функции и держать контекст задачи. То есть всё то, что сегодня лежит в основе современных AI-агентов, мультиагентных систем и автоматизации бизнес-процессов.
Поддержка function calling, системных инструкций и структурированного вывода делает Gemma 4 хорошей базой для прикладных решений. Например, для внутренних ассистентов, сервисных ботов, аналитических агентов, инструментов поддержки разработчиков или автономных workflow-движков. Ну и да — это уже вполне рабочая основа для мультиагентных систем, где несколько специализированных агентов делят роли и координируют действия между собой.
Есть и сильный блок по коду. Gemma 4 поддерживает качественную офлайн-генерацию кода, так что локальная рабочая станция может превратиться в полноценного AI-помощника для разработки. Для команд, которым важны приватность, контроль над исходниками и работа без постоянной отправки данных во внешние сервисы, это, честно говоря, очень весомый аргумент.
Мультимодальность тоже на месте. Все модели умеют работать с изображениями и видео, поддерживают разные разрешения и хорошо справляются с OCR, диаграммами и визуальным анализом. А компактные E2B и E4B дополнительно принимают аудиовход — для распознавания и понимания речи. Такая комбинация открывает дорогу к on-device AI, edge-автоматизации и локальным агентам, которые взаимодействуют с миром не только через текст.
- Продвинутое рассуждение: улучшенная работа с многошаговой логикой, математикой и сложными инструкциями.
- Агентные сценарии: function calling, JSON-ответы и системные инструкции для надёжной автоматизации.
- Генерация кода: локальный AI-ассистент для разработки без обязательной зависимости от облака.
- Мультимодальность: обработка изображений, видео, OCR, диаграмм, а в E2B и E4B — ещё и аудио.
- Длинный контекст: до 128K у edge-моделей и до 256K у старших версий.
- Многоязычность: обучение более чем на 140 языках.
Отдельно стоит сказать о контекстном окне. Edge-модели поддерживают 128K, а более крупные — до 256K токенов. Это уже позволяет работать с длинными документами, репозиториями, внутренними базами знаний и сценариями, где критична агентная память и RAG. Не идеально для всего на свете, конечно, но очень, очень практично.
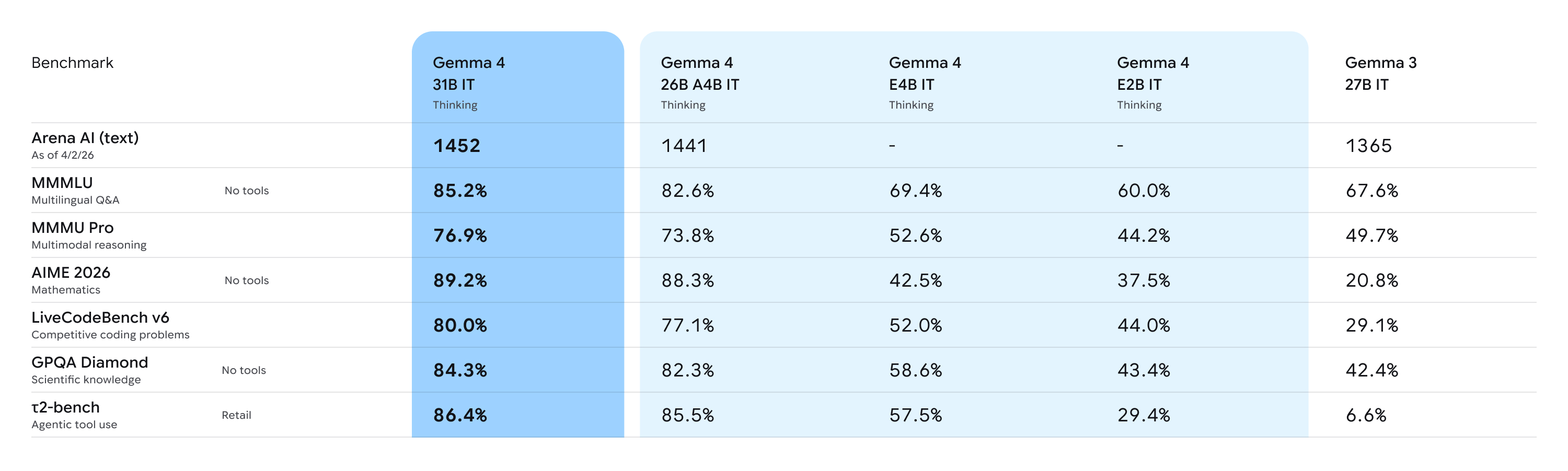
Модели оценивались на широком наборе датасетов и метрик. Подробности доступны в model card.
Какая модель для чего подходит
26B и 31B: серьёзный интеллект на локальных машинах
Старшие модели рассчитаны на исследователей, инженерные команды и продуктовые группы, которым нужен высокий уровень reasoning без обязательного перехода в закрытые облачные платформы. Неквантованные веса в формате bfloat16 помещаются на один NVIDIA H100 с 80 ГБ памяти, а квантованные версии можно запускать и на потребительских GPU. Это делает Gemma 4 вполне пригодной для локальных IDE, coding assistants, автономных агентов и корпоративных AI-инструментов.
Модель 26B построена по схеме Mixture of Experts и во время инференса активирует только 3,8 млрд параметров. За счёт этого она особенно хороша там, где критична скорость отклика. 31B Dense, напротив, делает ставку на максимальное качество и выглядит сильной базой для дообучения под специализированные задачи. Тут уже всё зависит от приоритетов: где-то важнее latency, где-то — потолок качества. В жизни так и бывает, универсальной кнопки нет.
E2B и E4B: интеллект для мобильных и edge-устройств
Компактные модели E2B и E4B проектировались с прицелом на вычислительную эффективность и экономию памяти. Во время инференса они используют эффективный объём в 2 и 4 млрд параметров, что помогает беречь RAM и заряд батареи. В сотрудничестве с командами Pixel, Qualcomm Technologies и MediaTek Google добилась того, что эти мультимодальные модели могут работать офлайн и почти без задержки на edge-устройствах — от смартфонов до Raspberry Pi и NVIDIA Jetson Orin Nano.
Для Android-разработчиков это особенно интересно: уже сейчас можно прототипировать агентные сценарии в AICore Developer Preview с расчётом на будущую совместимость с Gemini Nano 4. А если смотреть шире, Gemma 4 хорошо ложится в тренд на локальные AI-агенты, встроенную автоматизацию и распределённые интеллектуальные системы, где часть логики живёт прямо на устройстве. Без постоянного похода в облако. Иногда это не просто удобно — это принципиально.
Открытая лицензия и свобода внедрения
Gemma 4 выходит по лицензии Apache 2.0. Для разработчиков и компаний это не формальность, а реальное преимущество. Такая лицензия упрощает коммерческое использование, снижает барьеры для интеграции и даёт больше контроля над тем, как именно модель будет использоваться в продукте, инфраструктуре или исследовательском проекте.
На практике это означает гибкость: можно разворачивать решения on-premises, в частном облаке или в гибридной среде, не теряя контроль над данными, моделью и вычислительным контуром. Для организаций, которые думают о цифровом суверенитете, защите данных и регуляторных ограничениях, это особенно важно. И тут Gemma 4 хорошо сочетается с задачами вроде AI compliance и соответствия требованиям, где мало просто «запустить модель» — нужно ещё понимать, как она встроена в процессы, кто контролирует данные и как обеспечивается управляемость.
«Выпуск Gemma 4 по лицензии Apache 2.0 — это важная веха. Мы очень рады поддерживать семейство Gemma 4 на Hugging Face с первого дня».
Безопасность и доверие — не в довесок, а в основе
Google подчёркивает, что Gemma 4 проходит те же строгие процедуры инфраструктурной безопасности, что и закрытые модели компании. Для предприятий это важный сигнал: открытость здесь не означает компромисс по надёжности. Скорее наоборот — появляется возможность совместить прозрачность, контроль и высокий уровень качества.
Если смотреть на рынок трезво, именно это и нужно большинству компаний. Не просто мощная модель, а модель, которую можно встроить в корпоративный контур, защитить, масштабировать и использовать в реальных процессах — от внутренних ассистентов до сложной AI-автоматизации. Без лишнего шума. Без фокусов. Просто рабочий инструмент, и это, если честно, дорогого стоит.
В итоге Gemma 4 выглядит как сильная открытая база для нового поколения AI-приложений: локальных, мультимодальных, агентных и управляемых. Для разработчиков — простор для экспериментов. Для бизнеса — шанс строить собственные AI-системы без жёсткой привязки к закрытым платформам. А дальше, ну, всё зависит от того, кто и как этим воспользуется.