
Состояние AI-агентов в 2026 году: внедрение, архитектура, безопасность и вывод в production
Состояние AI-агентов
В опросе приняли участие более 1 300 специалистов — инженеры, product-менеджеры, руководители направлений и топ-менеджеры. Картина получилась без прикрас: AI-агенты уже вышли за пределы экспериментов, но путь к надежному production по-прежнему усеян вполне земными проблемами — качеством, скоростью, безопасностью и управляемостью.
Введение
На старте 2026 года компании уже почти не спорят о том, нужны ли им AI-агенты. Спор теперь другой — как довести их до ума, как встроить в процессы без хаоса и как сделать так, чтобы система не рассыпалась при первом же росте нагрузки. И это, честно говоря, куда более взрослый разговор.
Опрос более чем 1 300 специалистов показал, как бизнес подходит к разработке AI-агентов и автоматизации, какие сценарии действительно работают и где команды чаще всего буксуют.
Главное — коротко:
- Выход в production уже не редкость: 57% респондентов сообщили, что их AI-агенты работают в production, а крупные компании идут впереди остальных.
- Качество остается главным стоп-фактором: 32% назвали его основным барьером. При этом тревога из-за стоимости заметно снизилась.
- Наблюдаемость стала обязательной: почти 89% организаций внедрили инструменты observability для агентов, тогда как полноценные evals есть у 52%.
- Мульти-модельный подход стал нормой: OpenAI лидирует, но Gemini, Claude и open source-модели используются очень широко. Fine-tuning пока остается скорее точечным инструментом, чем стандартом.
Ключевые наблюдения
Что вообще понимают под agent engineering?
Agent engineering — это не просто «подключили LLM и поехали». Речь об итеративной инженерной дисциплине, в которой языковую модель превращают в надежную, проверяемую и управляемую систему. Поскольку поведение агентов недетерминировано, командам приходится быстро тестировать, пересобирать, измерять и снова улучшать результат — да, по кругу, но иначе не работает.
Крупные компании лидируют по внедрению
Более половины опрошенных — 57,3% — уже используют агентов в production. Еще 30,4% находятся в активной разработке и имеют конкретные планы по запуску.
Это заметный рост относительно прошлого года, когда о production-внедрении сообщили 51% участников. Иными словами, рынок сдвинулся: proof-of-concept уже не выглядит финальной остановкой. Скорее наоборот — компании массово переходят от демонстраций к реальным системам, которые должны приносить пользу, а не просто красиво выглядеть на слайде.
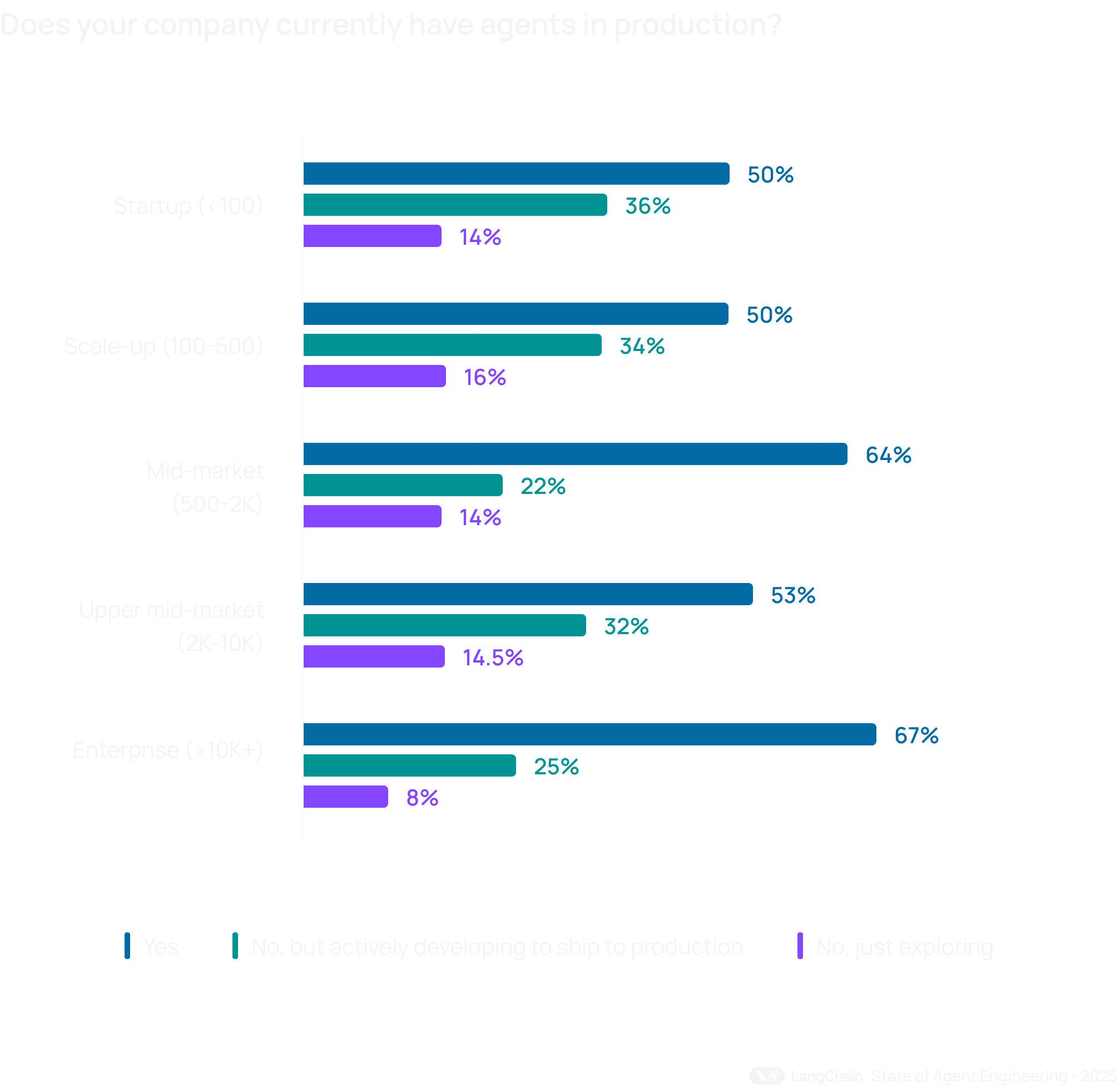
Что меняется с ростом масштаба?
Среди организаций с численностью 10 000+ сотрудников 67% уже вывели агентов в production, а еще 24% активно готовят запуск. Для компаний с численностью менее 100 сотрудников эти показатели составили 50% и 36% соответственно.
Вывод довольно прямой: крупный бизнес быстрее переводит пилоты в устойчивые решения. Вероятно, дело в инвестициях в платформенные команды, зрелую архитектуру AI-агентов, процессы надежности и, конечно, безопасность. Без этого масштабирование обычно идет не бодрым маршем, а с характерным скрипом.
Основные сценарии использования
Клиентский сервис оказался самым распространенным сценарием применения AI-агентов — 26,5%. Сразу за ним идут исследования и анализ данных — 24,4%. В сумме эти два направления дают больше половины всех основных production-сценариев.
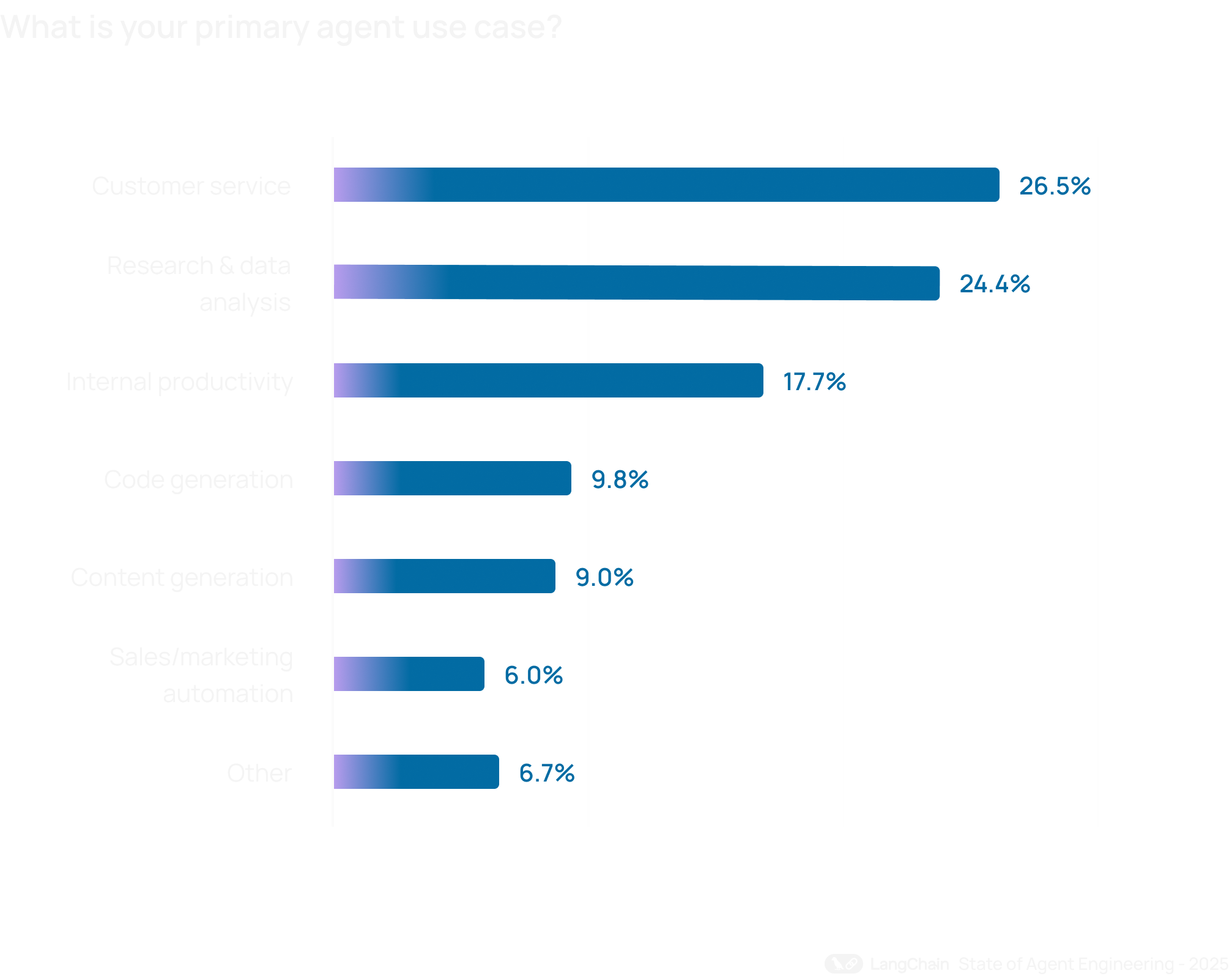
Сильные позиции клиентского сервиса показывают важный сдвиг: агенты все чаще выходят на передовую, то есть взаимодействуют не только с сотрудниками, но и с клиентами напрямую. А это уже совсем другой уровень ответственности. Ошибка внутреннего помощника неприятна. Ошибка внешнего агента — это уже репутация, деньги и иногда юридические риски.
При этом внутренние процессы никуда не делись: 18% респондентов используют агентов для автоматизации внутренних workflow и повышения продуктивности сотрудников. Такой подход особенно характерен для компаний, которые хотят сначала обкатать агентные системы внутри, а уже потом выпускать их наружу.
Популярность сценариев, связанных с исследованиями и аналитикой, тоже закономерна. Сегодня AI-агенты особенно сильны там, где нужно собрать разрозненные данные, сопоставить источники, удержать контекст и выдать осмысленный результат. Не магия — просто хорошая работа с информацией. Хотя иногда выглядит почти как магия, да.
Интересно и другое: в этом году ответы оказались заметно более разнообразными. Похоже, внедрение AI-агентов постепенно выходит за рамки пары «канонических» кейсов и начинает расползаться по бизнес-функциям шире, чем раньше.
Что меняется в крупных организациях?
В компаниях с численностью 10 000+ сотрудников на первое место выходит внутренняя продуктивность — 26,8%. Далее следуют клиентский сервис (24,7%) и исследования с анализом данных (22,2%). Похоже, крупные компании чаще начинают с внутренних задач: автоматизируют поддержку сотрудников, поиск знаний, рутинные операции, а уже затем масштабируют внешние сценарии.
Это, кстати, вполне здравая логика. Внутри компании проще контролировать риски, быстрее собирать обратную связь и спокойнее выстраивать мультиагентные системы под реальные процессы.
Главные барьеры для production
Качество по-прежнему остается главным препятствием для вывода AI-агентов в production. В этом году треть респондентов назвали его основным блокером. Под качеством здесь понимают не что-то абстрактное, а вполне конкретные вещи: точность, релевантность, стабильность ответов, соблюдение нужного тона, соответствие бренд-гайдам и внутренним политикам.

На втором месте — задержка ответа (20%). И это неудивительно. Когда агент работает в клиентском сервисе, помогает писать код или участвует в бизнес-процессе в реальном времени, медлительность бьет по пользовательскому опыту почти так же больно, как и ошибки. Иногда даже сильнее: хороший ответ через минуту — это уже не всегда хороший ответ.
Здесь возникает знакомый компромисс: более сложные, многошаговые агенты часто дают лучший результат, но отвечают медленнее. А бизнес, как водится, хочет и быстро, и точно, и дешево, и чтобы без сюрпризов. Ну конечно.
При этом стоимость упоминается реже, чем в предыдущие годы. Похоже, снижение цен на модели и рост инженерной эффективности сместили фокус: команды меньше думают о цене одного вызова и больше — о том, чтобы агент работал надежно, предсказуемо и без странностей.
Что меняется при масштабировании?
В enterprise-компаниях с численностью 2 000+ сотрудников качество остается главным барьером, но на второе место выходит безопасность: ее указали 24,9% респондентов. Для более мелких организаций чаще острее стоит вопрос latency.

Для организаций с 10 000+ сотрудников ответы в свободной форме особенно часто указывали на галлюцинации и нестабильность выходных данных как на главный вызов в обеспечении качества. Многие также отмечали сложности с контекстом: как его удерживать, как не терять важные детали, как не раздувать стоимость и задержку. В реальных проектах именно здесь часто нужна не просто настройка промптов, а продуманная агентная память и RAG.
И да, это тот случай, когда проблема редко решается одной кнопкой. Скорее серией неидеальных, но разумных инженерных решений.
Наблюдаемость AI-агентов
Для агентных систем наблюдаемость уже стала не «приятным дополнением», а базовой инженерной нормой. Если команда не видит, как агент проходит шаги, какие инструменты вызывает, где теряет контекст и почему принимает то или иное решение, отладка превращается в гадание на кофейной гуще. А это, мягко говоря, не лучший operational-подход.
89% организаций сообщили, что внедрили ту или иную форму observability для своих агентов. У 62% есть детализированный tracing, позволяющий разбирать отдельные шаги, вызовы инструментов и логику выполнения.

Среди тех, у кого агенты уже работают в production, показатели еще выше: 94% используют observability, а 71,5% имеют полноценный tracing. Это очень показательно. Когда агентная система становится частью реального бизнеса, прозрачность перестает быть опцией.
Без наблюдаемости невозможно надежно расследовать сбои, улучшать производительность, контролировать качество и объяснять поведение системы внутренним командам, заказчикам и аудиторам. Особенно если речь идет о regulated-среде, где важны безопасность AI-агентов и управляемость решений.
_%402x.png)
Оценка и тестирование
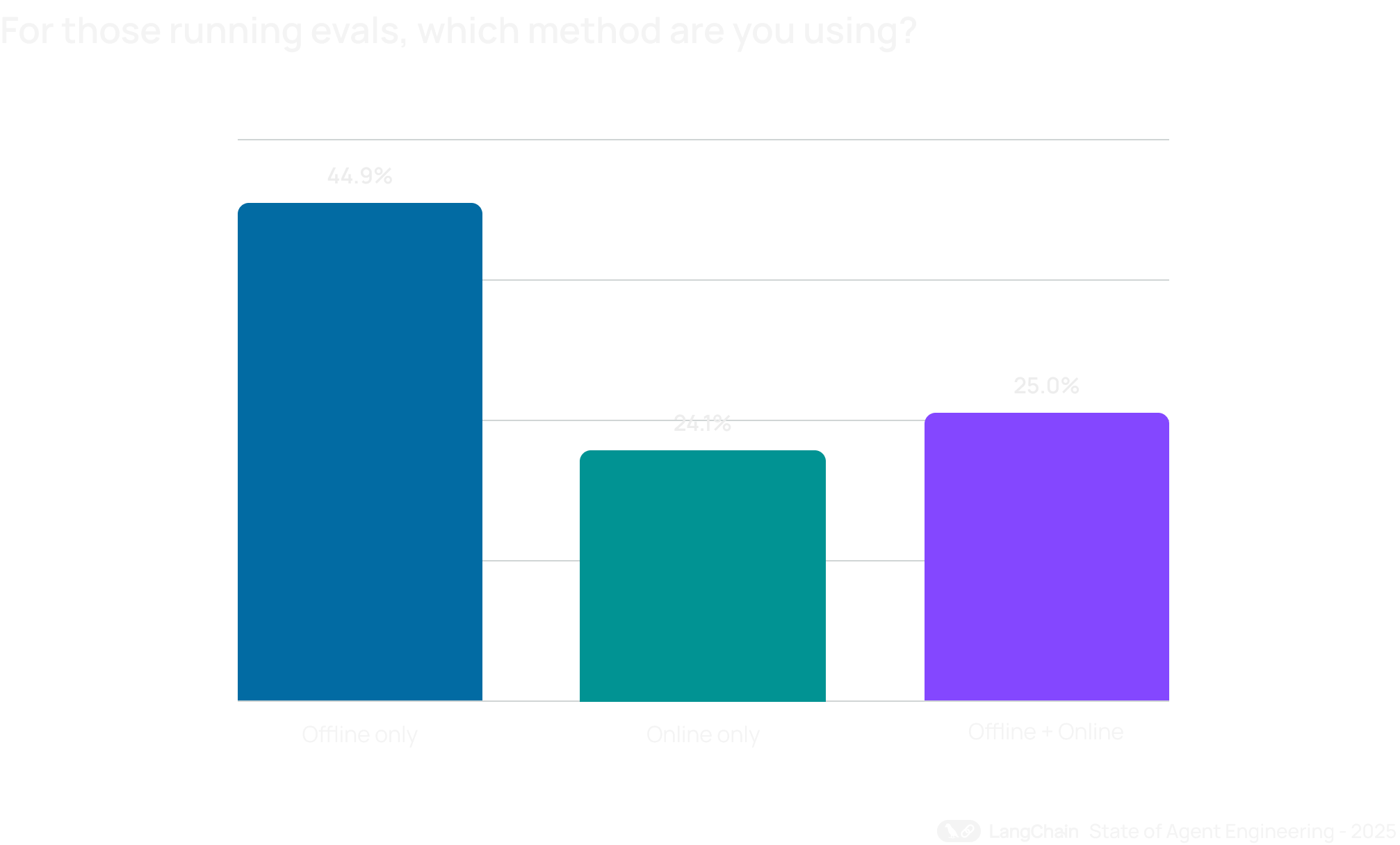
Хотя observability уже стала почти повсеместной практикой, системы оценки и тестирования AI-агентов пока догоняют. Чуть больше половины организаций — 52,4% — проводят offline evaluation на тестовых наборах. Это говорит о том, что команды понимают важность проверки регрессий и валидации поведения до релиза.
Online evaluation пока распространена меньше — 37,3%, — но ее доля растет по мере того, как агенты выходят в реальные процессы и начинают взаимодействовать с живыми пользователями, а не только с демонстрационными сценариями.

У организаций с production-агентами практики оценки выглядят зрелее: доля тех, кто вообще не проводит evals, снижается с 29,5% до 22,8%, а online evals используют уже 44,8%. Логика тут простая — после запуска нельзя полагаться только на лабораторные тесты. Нужны сигналы из реальной среды, иначе проблемы всплывут слишком поздно. Или слишком громко.
_%402x.png)
Большинство команд начинают с offline evals — порог входа ниже, настройка понятнее, результаты проще интерпретировать. Но постепенно многие приходят к комбинированной модели. Среди тех, кто вообще проводит evals, почти четверть совмещает offline и online evaluation.
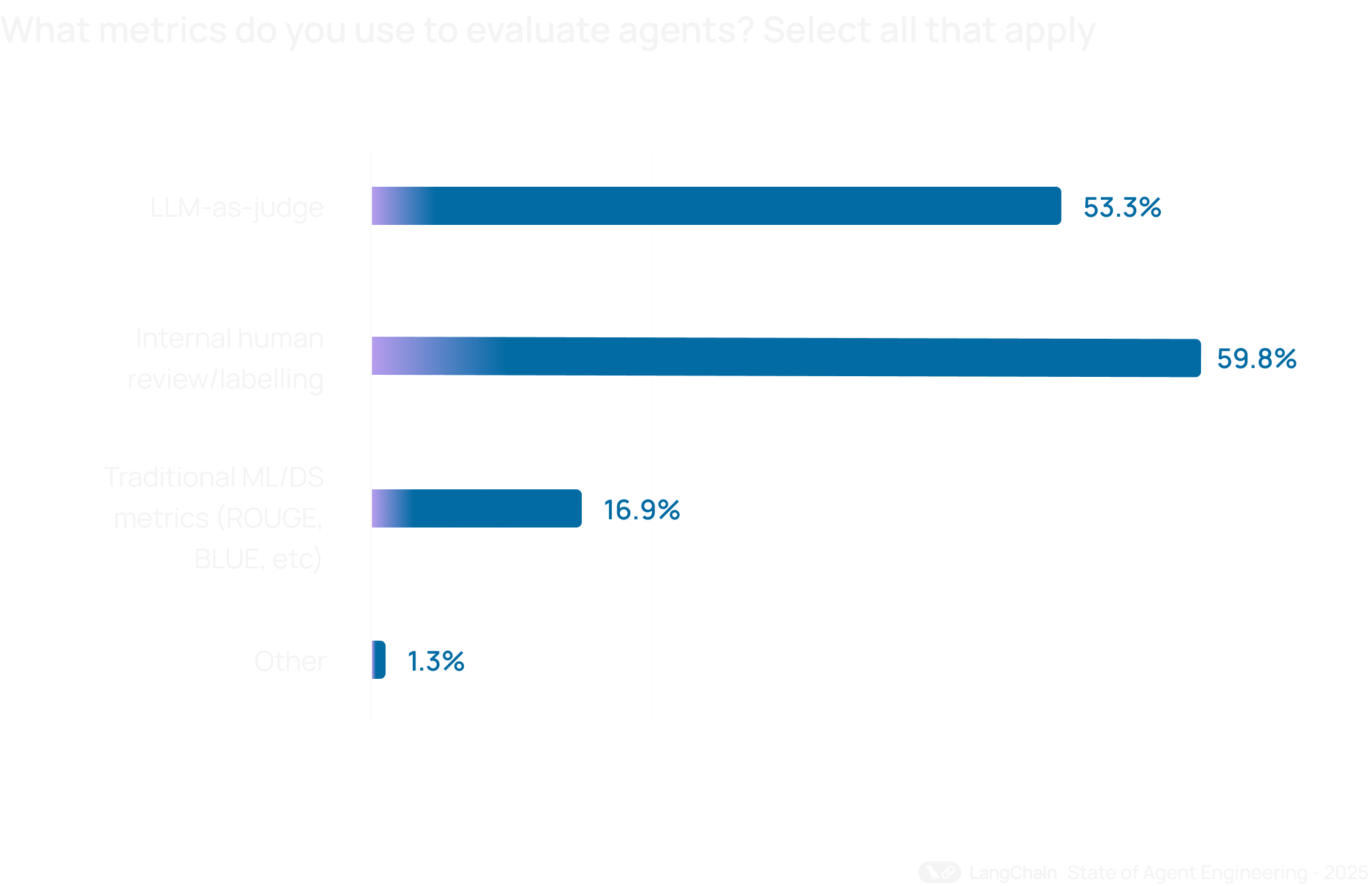
Что касается самих подходов, команды чаще всего используют сочетание человеческой проверки и автоматизированной оценки. LLM-as-judge дает масштаб и скорость, а human review — глубину и нюанс. Для сложных или чувствительных сценариев человеческая оценка по-прежнему незаменима: ее используют 59,8% организаций. Подходы LLM-as-judge применяют 53,3%.
А вот классические ML-метрики вроде ROUGE и BLEU используются ограниченно. Для открытых агентных взаимодействий, где допустимо несколько корректных ответов, они часто оказываются слишком грубыми. Скажем так: линейкой тут не все измеришь.
Ландшафт моделей и инструментов
Модели OpenAI по-прежнему лидируют по распространенности, но рынок уже явно ушел от идеи «один провайдер на все случаи жизни». Мульти-модельный подход стал новой нормой.
Более двух третей организаций используют GPT-модели OpenAI, однако свыше трех четвертей респондентов сообщили, что работают сразу с несколькими моделями — и в production, и на этапе разработки. Команды все чаще маршрутизируют задачи между моделями в зависимости от сложности, стоимости, задержки, требований к качеству и ограничений по данным.

Несмотря на удобство коммерческих API, запуск моделей внутри собственной инфраструктуры остается важной стратегией. Около трети организаций инвестируют в инфраструктуру и экспертизу для развертывания моделей in-house. Причины понятны: оптимизация затрат при больших объемах, требования к локализации данных, суверенитет данных и регуляторные ограничения в чувствительных отраслях.
Fine-tuning при этом остается скорее специализированной практикой. 57% организаций не занимаются дообучением моделей, предпочитая использовать базовые модели в связке с prompt engineering, retrieval и RAG-подходами. И это, в общем, не удивляет: fine-tuning требует данных, разметки, инфраструктуры, MLOps-поддержки и дисциплины. Много всего. Иногда слишком много для задачи, которую можно решить проще.

Отсюда и важный практический вывод: зрелая разработка AI-агентов сегодня все чаще строится не вокруг одной «идеальной» модели, а вокруг грамотной оркестрации — выбора модели под задачу, управления контекстом, памятью, инструментами и правилами исполнения. То есть вокруг инженерии системы целиком, а не вокруг одного API-ключа. Наконец-то.
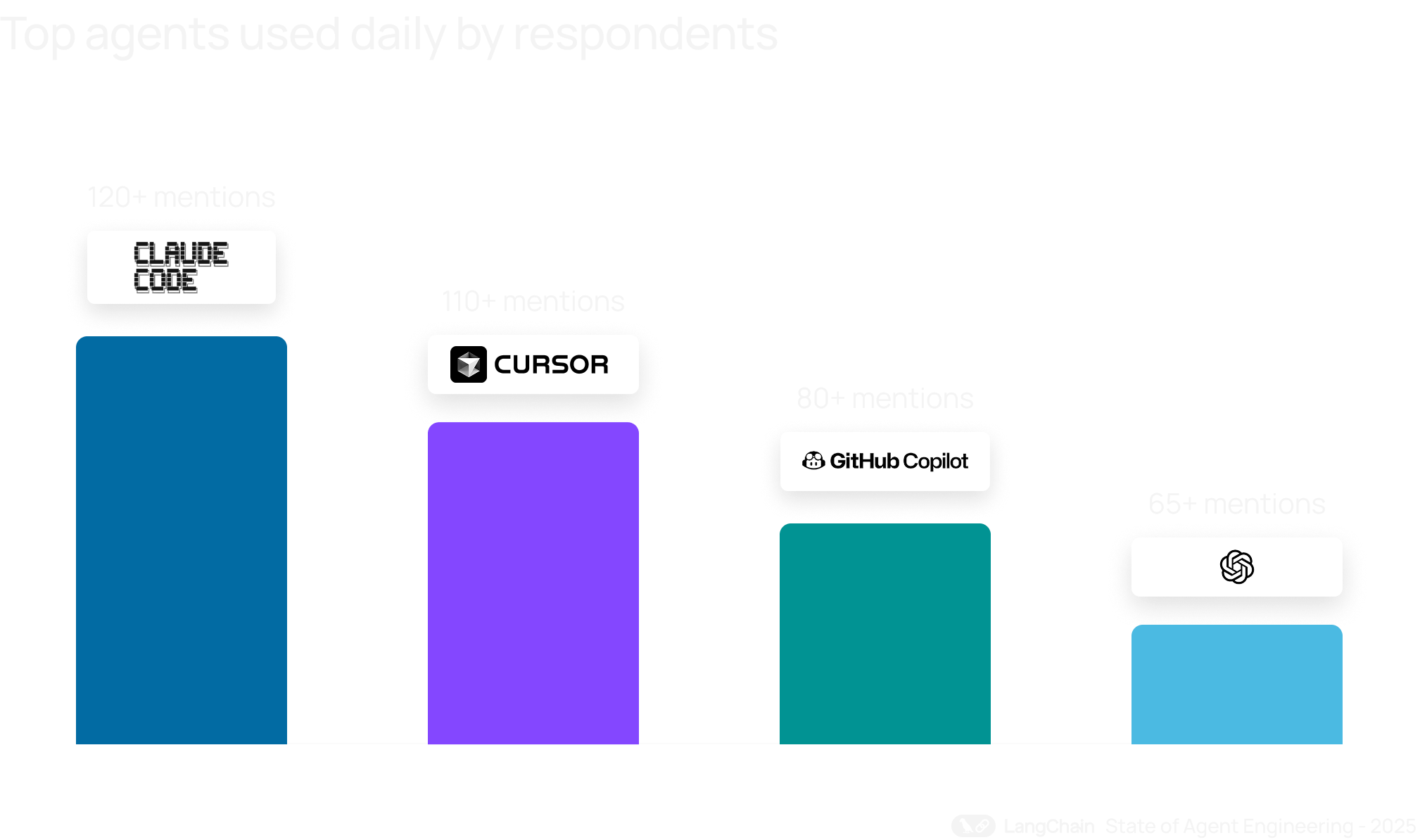
Какие агенты используют каждый день
Когда участников спросили: «Каких агентов вы чаще всего используете в повседневной работе?», в ответах довольно быстро проявились устойчивые паттерны.
1. Агенты для разработки кода уверенно лидируют.
Чаще всего респонденты упоминали coding-ассистентов: Claude Code, Cursor, GitHub Copilot, Amazon Q, Windsurf и Antigravity. Их используют для генерации кода, отладки, написания тестов, рефакторинга и навигации по большим codebase. Для многих это уже не эксперимент, а часть ежедневного рабочего ритма — почти как IDE, только разговорчивее.
2. Research- и deep research-агенты идут следом.
Второй крупный кластер — исследовательские агенты на базе ChatGPT, Claude, Gemini, Perplexity и похожих инструментов. Их используют для изучения новых тем, суммаризации длинных документов, анализа рынка, подготовки материалов и синтеза информации из разных источников. Часто такие агенты работают в паре с coding-ассистентами в рамках одного workflow.
3. Кастомные AI-агенты тоже занимают заметное место.
Третья группа ответов касалась собственных, кастомно разработанных агентов — нередко на базе LangChain и LangGraph. Респонденты описывали внутренние решения для QA-тестирования, поиска по корпоративным базам знаний, SQL и text-to-SQL, планирования спроса, клиентской поддержки и автоматизации бизнес-процессов.
При этом заметная часть участников призналась, что пока не использует агентов за пределами LLM-чата или помощи в программировании. Это важный сигнал: AI-агенты уже широко вошли в повседневную практику, но идея тотальной agentic-автоматизации пока все еще находится на ранней стадии. То есть рынок уже разогнался, но до полной зрелости ему еще ехать и ехать.
Методология
Данные этого отчета собраны на основе публичного опроса, который проводился в течение двух недель — с 18 ноября по 2 декабря 2025 года. Всего было получено 1 340 ответов.
Топ отраслей среди участников:
- Технологии — 63%
- Финансовые услуги — 10%
- Здравоохранение — 6%
- Образование — 4%
- Потребительские товары — 3%
- Производство — 3%
Размер компаний:
- Менее 100 сотрудников — 49%
- 100–500 сотрудников — 18%
- 500–2 000 сотрудников — 15%
- 2 000–10 000 сотрудников — 9%
- 10 000+ сотрудников — 9%
Если смотреть на результаты в целом, вывод напрашивается довольно ясный: рынок AI-агентов быстро взрослеет. Но взросление это не глянцевое. С ростом внедрения на первый план выходят не вау-демо, а архитектура, безопасность, качество, агентная память, тестирование и AI compliance и соответствие требованиям. Именно здесь и будет решаться, какие агентные системы останутся игрушками, а какие станут реальной частью бизнеса.


