
8 уровней agentic engineering: как AI-агенты меняют разработку, автоматизацию и архитектуру команд
AI уже пишет код так быстро, что у многих команд, если честно, не модели отстают — отстают привычки. Отсюда и странный перекос: все обсуждают рекорды на SWE-bench, а инженерных руководителей волнует совсем другое — скорость поставки, качество изменений, предсказуемость релизов, нагрузка на ревью. И вот тут начинается самое интересное. Одна команда на тех же моделях собирает рабочий продукт за считаные дни, а другая вязнет в бесконечном POC, который то падает, то «почти готов». Разница обычно не в магии. Разница в инженерной дисциплине вокруг AI.
Этот разрыв не закрывается одним удачным промптом. Он схлопывается ступеньками — уровень за уровнем. Их, по наблюдениям Бассима Эледата, восемь. И да, прогресс тут не всегда линейный: кто-то рано осваивает оркестрацию, но проваливается в контексте; кто-то отлично пишет rules-файлы, но не умеет выстраивать обратную связь. Бывает. Жизнь вообще редко идет по красивой схеме.
Есть и еще одна штука, о которой часто забывают: продуктивность в agentic engineering — командный вид спорта. Можно быть хоть «магом 7-го уровня», поднимать качественные PR фоном и просыпаться уже с готовыми изменениями, но если сосед по репозиторию все еще вручную, медленно и с тоской проверяет каждую строчку, throughput упрется именно в него. Поэтому развитие AI-агентов и автоматизации разработки — это не только про личную эффективность, но и про зрелость всей команды.
Ниже — отредактированная и адаптированная версия этой шкалы. Без лишнего глянца. По делу.
Уровни 1 и 2: Tab Complete и AI-IDE
Первые два уровня — база. Пролетим их быстро.
Сначала был Copilot и старая добрая механика tab complete: начал писать — нажал Tab — получил продолжение. Для опытных разработчиков это работало особенно хорошо, потому что они уже держали архитектуру в голове и просто ускоряли рутину. AI здесь не думал за них, он скорее подносил кирпичи.
Потом появились IDE, заточенные под работу с агентами, вроде Cursor. И вот тут игра заметно изменилась: чат получил доступ к кодовой базе, правки в нескольких файлах стали проще, а взаимодействие — естественнее. Но потолок оставался прежним: все упиралось в контекст. Если модель не видит нужный фрагмент системы — она фантазирует. Если видит слишком много мусора — тоже фантазирует. В общем, либо слепая, либо перегруженная.
На этих уровнях многие используют plan mode: сначала превращают идею в пошаговый план, потом уточняют его, потом уже запускают реализацию. Это разумно. Особенно в начале. Позже зависимость от такого режима обычно снижается, но как тренировочные колеса — вещь полезная.
Уровень 3: Context Engineering
Если в 2025 году и было модное словосочетание, то это context engineering. И не зря. Как только модели стали более-менее стабильно следовать инструкциям, выяснилось: решает не только интеллект модели, но и то, какой именно контекст вы ей подаете, в каком объеме и в какой момент. Лишний шум вредил почти так же, как нехватка данных. Отсюда и мантра: каждый токен должен оправдывать свое присутствие.

На практике context engineering — это не только prompt. Совсем не только. Это system prompt, rules-файлы вроде .cursorrules и CLAUDE.md, описания tools, история диалога, правила выбора инструментов на каждом шаге. Это даже вопрос того, сколько инструментов вообще показывать модели: если вариантов слишком много, она начинает тратить силы не на задачу, а на разбор меню. Люди, кстати, делают ровно то же самое.
Сейчас про context engineering говорят чуть тише: большие context window и более устойчивые модели сделали среду менее хрупкой. Но проблема никуда не делась, просто стала тоньше. Особенно она заметна там, где:
- Используются небольшие модели. Они чувствительнее к качеству контекста, а еще размер окна напрямую влияет на latency и время до первого токена.
- Подключены «тяжелые» инструменты и модальности. Изображения, браузерные MCP, большие схемы tools — все это быстро съедает токены.
- Агенту выдали десятки инструментов сразу. Тогда он начинает больше читать описания инструментов, чем реально работать.
Иными словами, context engineering не умер. Он просто повзрослел. Теперь задача не только в том, чтобы убрать плохой контекст, а в том, чтобы подать правильный контекст ровно тогда, когда он нужен. Это уже прямая дорожка к агентной памяти и RAG, где нужные знания поднимаются по запросу, а не валятся на модель одной кучей.
Уровень 4: Compounding Engineering
Context engineering улучшает текущую сессию. Compounding engineering делает так, чтобы следующая сессия стала умнее предыдущей. Вот это уже серьезно.
Суть подхода — в цикле plan, delegate, assess, codify. Сначала вы планируете задачу и даете модели достаточно опоры. Потом делегируете. Затем оцениваете результат. А после — и это ключевой момент — фиксируете полученное знание: что сработало, где агент ошибся, какие паттерны стоит сохранить, а какие лучше больше не повторять. Не романтика, да. Но очень эффективно.
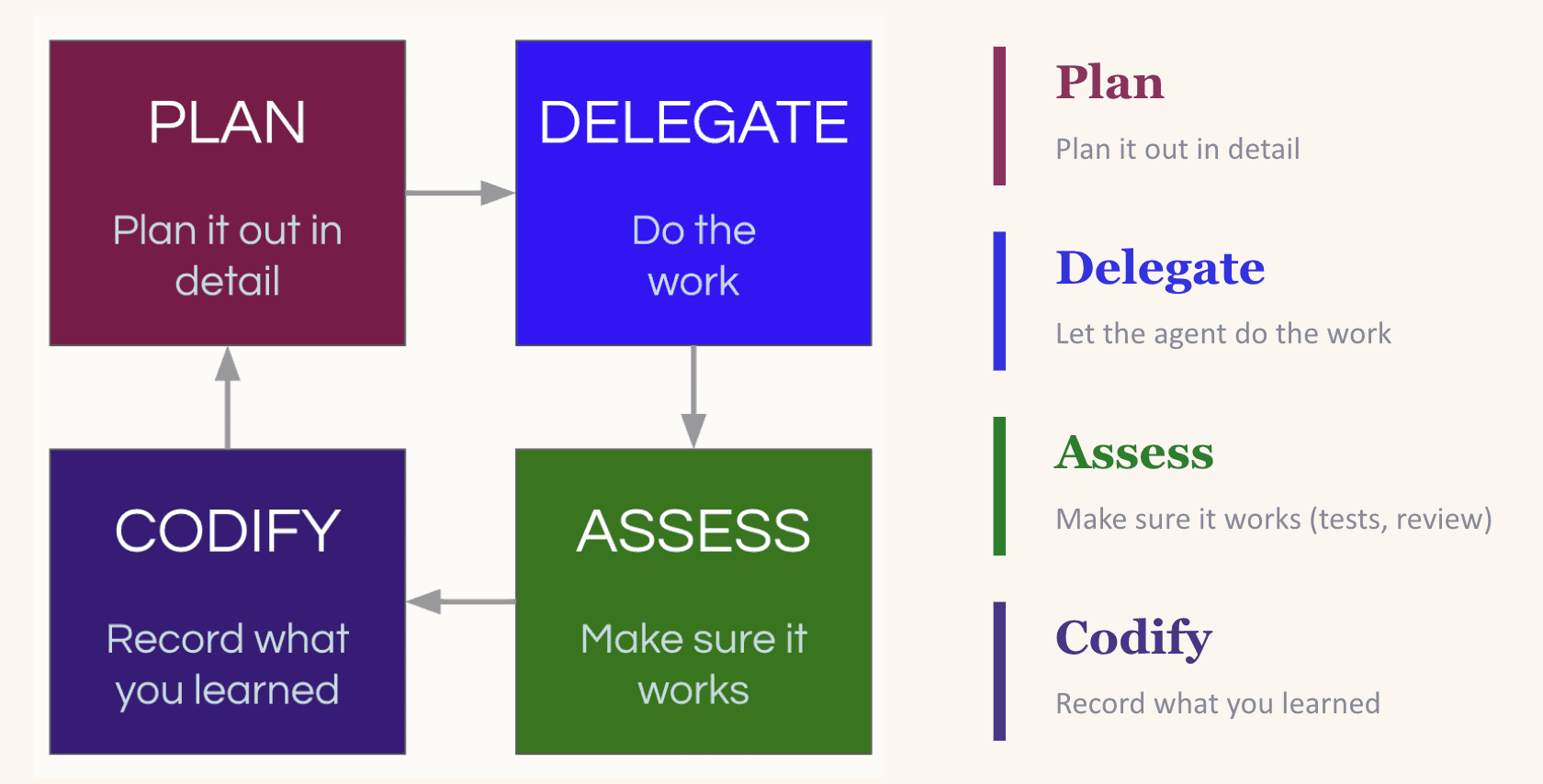
Почему это важно? Потому что LLM сами по себе не накапливают устойчивый опыт. Если вчера вы вручную убрали ненужную зависимость, а сегодня не зафиксировали это правило, завтра модель с невинным видом добавит ее обратно. И глазом не моргнет. Самый очевидный способ замкнуть цикл — обновлять CLAUDE.md или аналогичный rules-файл. Но тут легко переборщить: если записать туда вообще все, файл превратится в свалку инструкций, а модель перестанет различать главное и второстепенное.
Гораздо практичнее строить среду, где полезный контекст можно найти естественно: поддерживать живую папку docs/, структурировать знания, выстраивать понятную навигацию по репозиторию. Это уже не просто удобство, а элемент архитектуры AI-агентов.
Люди, хорошо освоившие compounding engineering, почти рефлекторно ищут причину ошибки не в «тупой модели», а в том, какого контекста ей не хватило. И, честно говоря, в этом часто есть правда.
Уровень 5: MCP и Skills
Если уровни 3 и 4 решают проблему контекста, то уровень 5 решает проблему возможностей. Модель перестает быть просто собеседником в IDE и получает руки: доступ к API, базе данных, CI/CD, design system, браузерному тестированию, уведомлениям, внутренним сервисам. Она уже не просто рассуждает о коде — она действует.
MCP и кастомные skills здесь становятся центральным механизмом. Например, одна команда может собрать общий skill для PR review: один субагент проверяет безопасность работы с БД, другой — сложность и признаки overengineering, третий — качество prompts и соблюдение внутренних стандартов, четвертый гоняет линтеры и Ruff. Получается не «один умный бот», а распределенная проверка по ролям. Почти мини-команда. Почти.
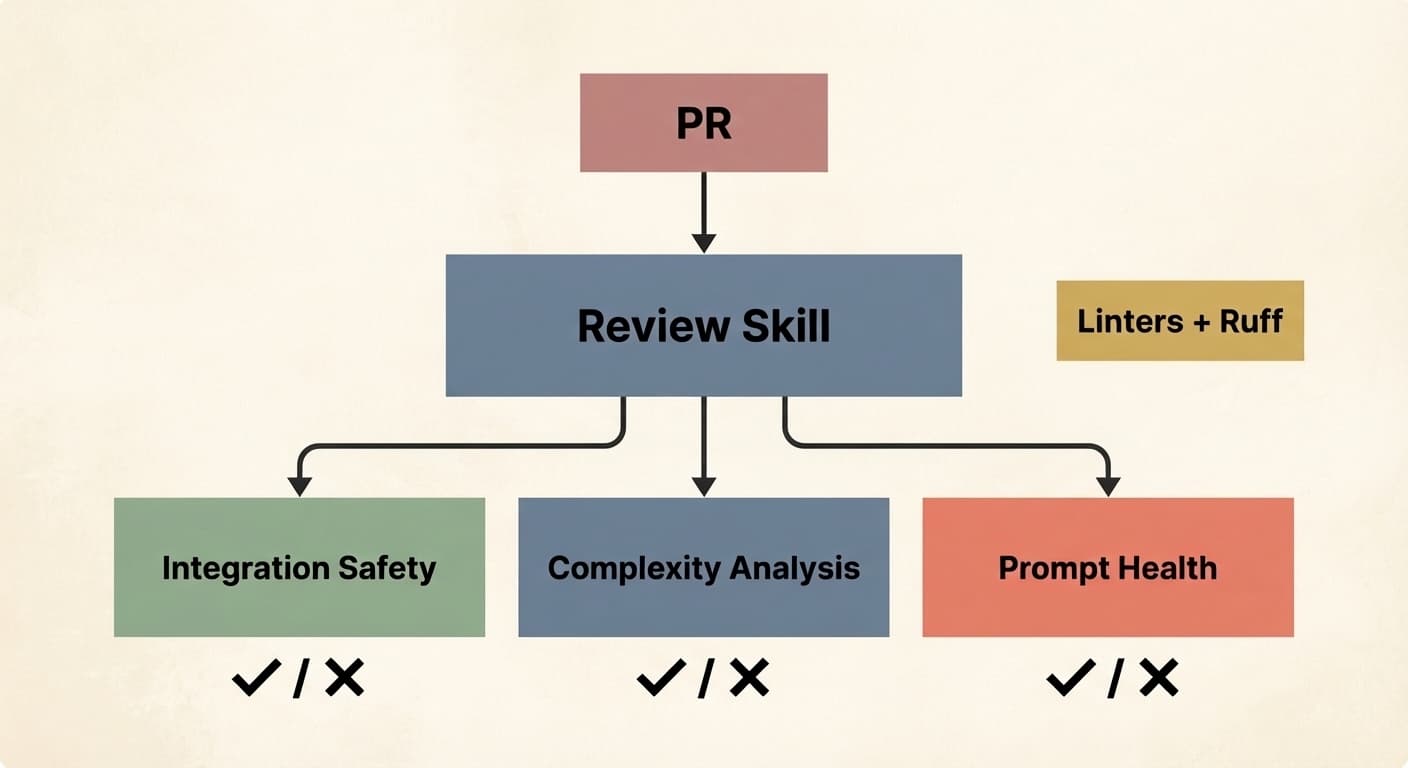
Именно здесь многие компании впервые по-настоящему ощущают ценность мультиагентных систем. Не в абстрактных демо, а в реальной инженерной работе: когда разные агенты специализируются, а не пытаются быть мастерами на все руки.
Есть и важный сдвиг в инструментарии. Все чаще вместо MCP используют CLI tools. Причина прозаична: токены стоят денег и времени. MCP нередко тащит в контекст полные схемы инструментов на каждом ходе, даже если агент ими не пользуется. CLI-подход экономнее: запускается точечная команда, в окно контекста попадает только релевантный вывод. Грубо говоря, меньше болтовни — больше пользы.
Но вот что важно. Если на этом этапе у вас шумный контекст, плохо описанные tools и расплывчатые prompts, дальнейшая автоматизация не спасет. Она просто быстрее масштабирует бардак. Да, звучит грубовато. Но так и есть.
Уровень 6: Harness Engineering и автоматические циклы обратной связи
Вот тут, как говорится, начинается настоящий разгон.
Harness engineering — это уже не про отдельный prompt и не про удачно подобранный tool. Это про среду, в которой агент способен работать надежно, долго и почти без ручного сопровождения. Ему нужен не просто редактор, а полноценный контур обратной связи: тесты, логи, браузер, наблюдаемость, проверки, ограничения, сигналы об ошибках. Иначе автономность превращается в дорогой способ производить мусор с уверенным лицом.
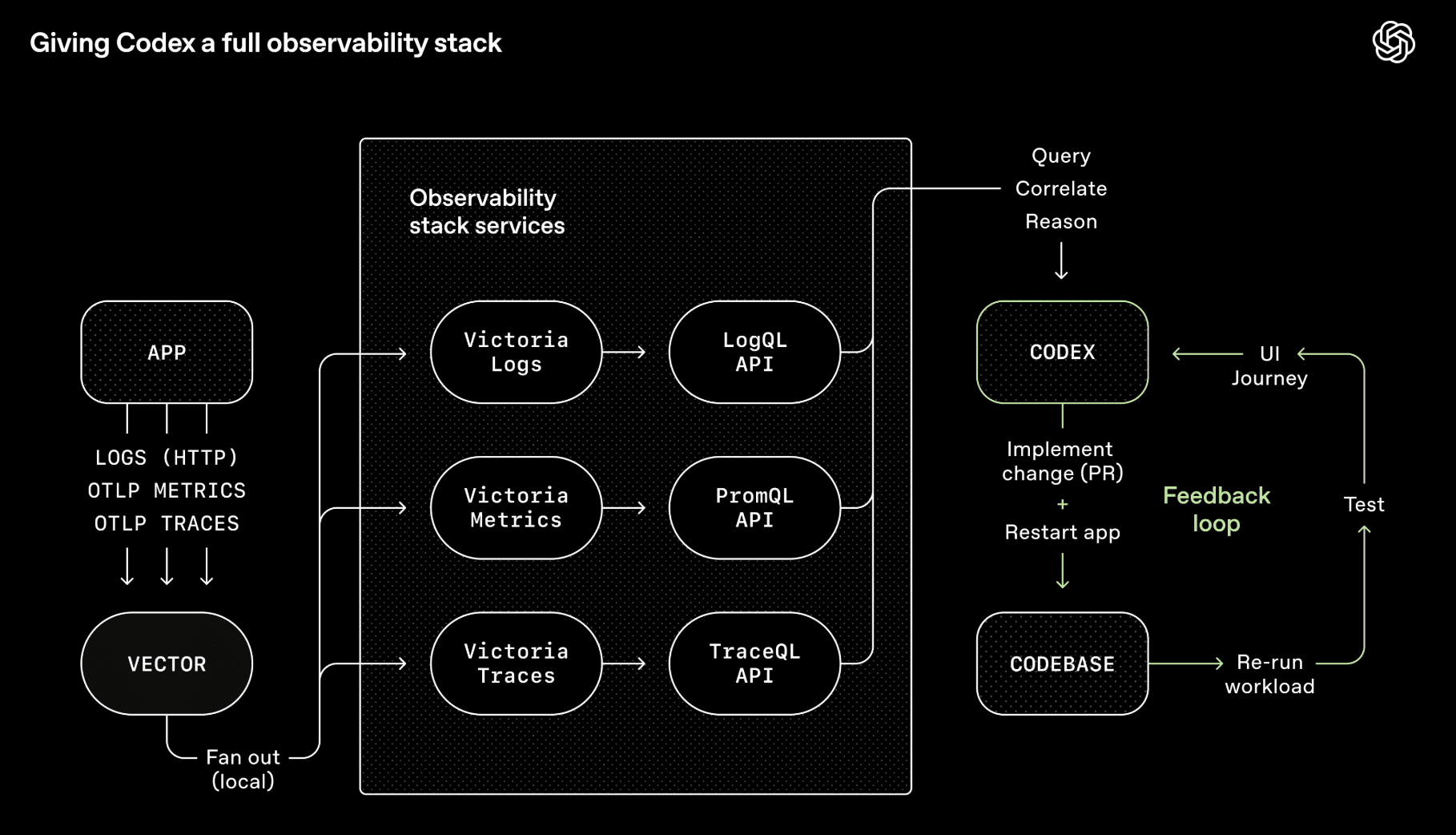
Именно так работают зрелые агентные контуры: агент воспроизводит баг, собирает артефакты, вносит исправление, сам же его валидирует, открывает PR, отвечает на замечания и эскалирует вопрос человеку только там, где действительно требуется суждение. Это уже не «AI помогает писать код». Это почти операционная система для инженерной автоматизации.
Ключевое понятие здесь — backpressure. То есть механизмы, которые не дают агенту бесконтрольно уехать в кювет: типизация, тесты, линтеры, pre-commit hooks, sandbox, policy checks, ограничения доступа. Хорошая безопасность AI-агентов строится именно так — не на доверии, а на границах. Если prompt injection спрятан в логах, а агент имеет доступ и к коду, и к секретам, и к продовым данным в одном контуре, беды долго ждать не придется. Совсем недолго.
На этом уровне особенно полезны два принципа:
- Проектируйте под throughput, а не под идеальность каждого коммита. Если требовать совершенства на каждом шаге, агенты начнут топтаться на месте и бесконечно перетирать одно и то же.
- Ограничения важнее инструкций. Чек-листы быстро устаревают, а четко заданные рамки работают дольше и надежнее.
Еще одна практическая деталь: агент должен уметь ориентироваться в репозитории без экскурсовода. Поэтому короткий AGENTS.md как оглавление, связанная документация и автоматическая проверка ее актуальности в CI — это не бюрократия, а инфраструктура автономии.
И вот после этого вопрос возникает сам собой: если агент умеет сам проверять свою работу, сам находить нужный контекст и сам исправлять ошибки — зачем человеку сидеть над ним постоянно?
Уровень 7: Background Agents
Непопулярная мысль, но все же: plan mode постепенно теряет статус обязательного ритуала.
Не потому, что планирование стало неважным. Наоборот. Просто хорошие модели при правильно выстроенной среде все чаще умеют планировать сами. Если у вас чистый контекст, внятные ограничения, рабочие tools и плотные feedback loops, отдельный этап «сначала человек вручную утверждает план» начинает растворяться. Не исчезает полностью — но уже не выглядит священной коровой.
На этом уровне планирование меняет форму. Оно становится не списком шагов, а исследованием: агент изучает кодовую базу, пробует варианты в worktrees, картирует пространство решений, задает уточняющие вопросы только там, где это действительно нужно. И все это — в фоне, пока вы заняты другим.
Вот он, настоящий переход: от «я жонглирую вкладками и чатами» к «работа идет без моего постоянного участия». Именно здесь background agents дают основной прирост производительности. Они могут асинхронно брать задачи, реализовывать изменения, поднимать PR, обновлять документацию, запускать проверки, чинить зависимости, готовить security fixes. А вы в это время — страшно сказать — занимаетесь более важными вещами.

Но тут появляется новая проблема: координация. Чем больше фоновых агентов вы запускаете, тем меньше вы похожи на разработчика и тем больше — на менеджера, который распределяет задачи, следит за зависимостями и разбирает завалы. Поэтому на уровне 7 почти неизбежно возникает orchestrator agent — диспетчер, который берет логистику на себя.
Практика показывает еще две важные вещи. Во-первых, разные модели хороши в разном: одна лучше реализует, другая сильнее в исследовании, третья строже ревьюит. Во-вторых — и это прямо критично — implementer и reviewer нужно разделять. Если одна и та же модель и пишет код, и проверяет его, она почти всегда будет к себе слишком добра. Ну а кто бы сомневался.
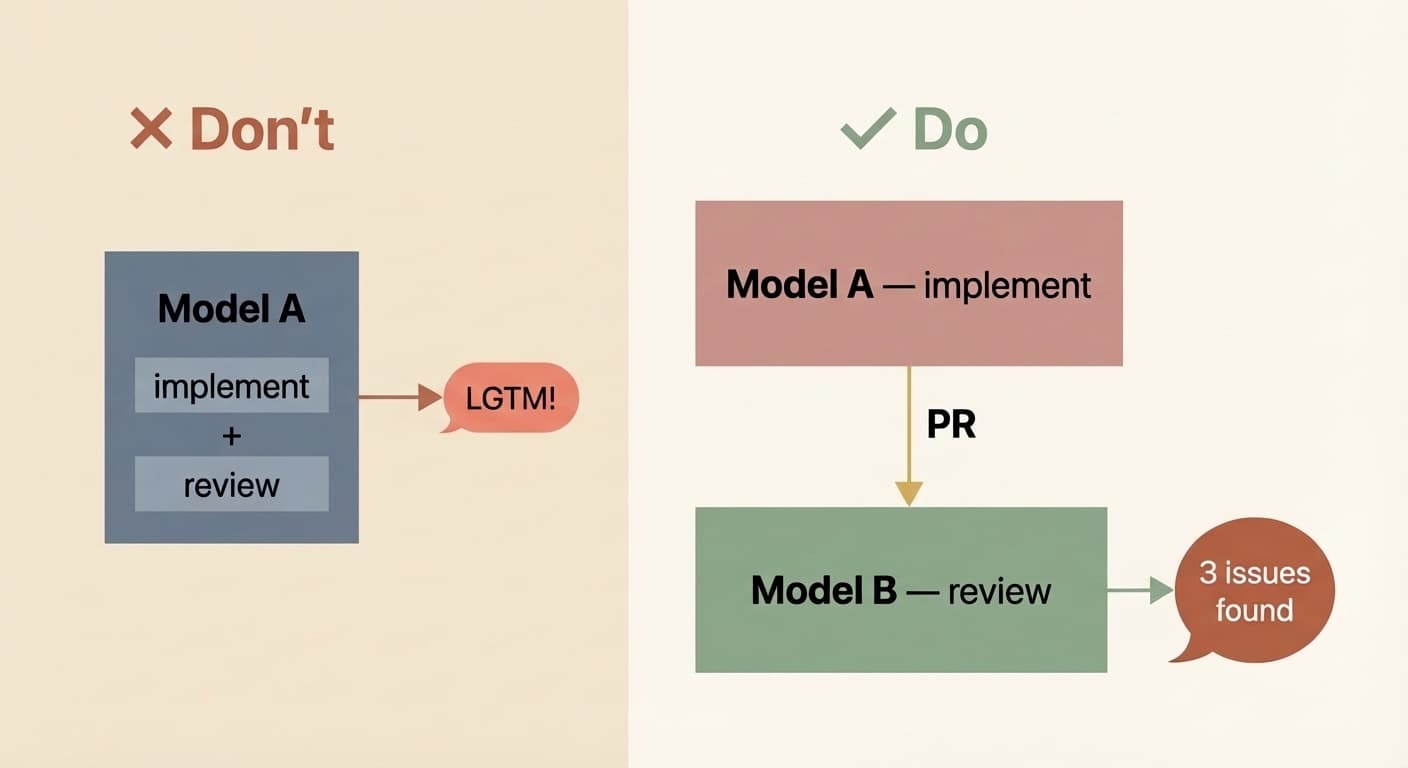
Именно здесь enterprise-команды начинают всерьез думать не только о скорости, но и о governance: кто что может запускать, где хранятся артефакты, как отслеживаются решения агентов, как обеспечивается аудит. То есть речь уже идет не просто об автоматизации, а о промышленной эксплуатации агентных систем.
Уровень 8: Автономные команды агентов
Этот уровень пока, по-честному, больше frontier, чем рутина. Да, отдельные компании уже подбираются к нему. Но массовой, устойчивой практикой он еще не стал.
Если на уровне 7 есть центральный orchestrator, который раздает задачи worker-агентам, то на уровне 8 это узкое место убирается. Агенты координируются напрямую: сами разбирают задачи, делятся промежуточными находками, помечают зависимости, синхронизируют изменения и пытаются разрешать конфликты без постоянного посредника. Звучит красиво. И местами работает. Но швы пока видны очень хорошо.
Эксперименты Anthropic и Cursor показали, что параллельная работа десятков и сотен агентов возможна, но без жестких ограничений и хорошего CI они начинают либо ломать существующий функционал, либо бесконечно осторожничать и топтаться на месте. Координация в мультиагентной архитектуре — это отдельная инженерная дисциплина, а не просто «давайте запустим побольше ботов».
Лично я бы не ставил на то, что большинство команд уже завтра перейдет на этот уровень. Модели все еще дорогие, небыстрые и не настолько надежные, чтобы автономные агентные команды стали экономически оправданным стандартом для повседневной разработки. Для большинства организаций главный выигрыш пока лежит на уровне 7. Там leverage огромный, а хаоса — все же поменьше.
Уровень ?
И, конечно, неизбежный вопрос: а что дальше?
Если вы уже умеете оркестрировать команды агентов почти без трения, нет особых причин, чтобы интерфейс навсегда оставался текстовым. Voice-to-voice взаимодействие с coding agent выглядит вполне естественным следующим шагом: не диктовка текста в чат, а нормальный разговор с системой, которая понимает намерение, смотрит на приложение, вносит изменения и тут же показывает результат. Дальше — кто знает. Может, и thought-to-thought когда-нибудь. Звучит диковато, да, но еще недавно и background agents казались чем-то из лаборатории.
Есть люди, которые гонятся за идеальным one-shot: сформулировал желание — и AI с первого раза собрал все безупречно. Возможно. Но, если уж совсем честно, проблема тут не только в моделях. Люди сами редко до конца понимают, чего хотят на старте. Разработка ПО всегда была итеративной, с возвратами, уточнениями, передумыванием на ходу. И, наверное, останется такой. Просто цикл станет быстрее. Намного быстрее.
Так что вопрос не в том, «заменят ли агенты инженеров». Вопрос в другом: на каком уровне работает ваша команда сейчас — и что мешает перейти на следующий? Иногда ответ сложный. А иногда до смешного простой: плохая документация, нет обратной связи, не выстроено AI compliance и соответствие требованиям, не определены границы безопасности. Мелочи, которые потом почему-то решают все.
На каком вы уровне?
1 / 7
Как вы обычно начинаете coding task с AI?