
Когда ML-эксперименты длятся не часы, а дни — а иногда и недели, — обычные AI-инструменты начинают буксовать. Они помогают по кусочкам: подсказать гипотезу, накидать конфиг, объяснить лог. Но довести исследование до результата целиком? Тут, как говорится, уже совсем другая лига.
Именно под такую задачу Meta создала Ranking Engineer Agent, или REA, — автономного AI-агента, который берет на себя ключевые этапы полного цикла работы с моделями ранжирования рекламы. По сути, это не просто помощник, а система, способная вести ML-эксперимент от идеи до следующей итерации почти без постоянного участия инженера.
- REA автономно выполняет важные этапы жизненного цикла ML для рекламных ranking-моделей Meta.
- В текущем материале речь идет прежде всего о сценариях ML-экспериментов: генерации гипотез, запуске training jobs, разборе сбоев и последовательном улучшении качества моделей.
- Агент умеет работать с длинными асинхронными процессами — от нескольких дней до нескольких недель — за счет механизма hibernate-and-wake; при этом стратегические решения по-прежнему остаются за человеком.
- В первом production-развертывании REA показал заметный эффект:
- до 2x по точности моделей — средняя точность на шести моделях выросла вдвое относительно baseline;
- до 5x по инженерной продуктивности — трое инженеров подготовили предложения по улучшению для восьми моделей, тогда как раньше на такой объем обычно уходило по два инженера на каждую модель.
Где тормозят классические ML-эксперименты
Рекламная инфраструктура Meta обслуживает миллиарды пользователей в Facebook, Instagram, Messenger и WhatsApp. За этим стоят сложные распределенные ML-системы, которые постоянно дорабатываются: нужно одновременно повышать качество пользовательского опыта и эффективность для рекламодателей. Задача, мягко говоря, не из простых.
Исторически цикл выглядел так: инженер формулирует гипотезу, проектирует эксперимент, запускает обучение, разбирает падения, анализирует метрики, потом идет на новый круг. И еще на один. И еще. Один полный проход мог занимать от нескольких дней до нескольких недель. По мере роста зрелости моделей находить действительно сильные улучшения становилось все труднее, а ручной, последовательный режим работы превратился в очевидное узкое место.
Отсюда и идея: нужен не просто copilot, а полноценный AI-агент для автоматизации сложных инженерных процессов, который умеет держать контекст, работать асинхронно и не теряться на длинной дистанции. В случае Meta таким агентом стал REA.
REA — не ассистент, а автономный исполнитель
Большинство AI-инструментов в ML-процессах реактивны. Им дают задачу — они отвечают. Сессия закончилась, контекст рассыпался, дальше инженер снова собирает картину вручную. Для коротких задач это терпимо. Для многодневных экспериментов — уже нет.
REA устроен иначе. Он спроектирован как автономная система, которая может координировать и продвигать экспериментальный цикл почти без постоянного ручного сопровождения. Не магия, конечно. Но близко к тому, что бизнес обычно ожидает от зрелой архитектуры AI-агентов: постоянное состояние, управляемая логика принятия решений, работа с ограничениями и память о предыдущих шагах.
Если коротко, REA закрывает три большие проблемы автономных ML-экспериментов.
- Длинный горизонт выполнения. Training jobs могут идти часами или сутками. Агент должен не просто «подождать», а сохранить состояние, не потерять нить рассуждений и корректно продолжить работу позже.
- Качественные и разнообразные гипотезы. Сильный эксперимент начинается с сильной идеи. REA комбинирует исторические результаты и исследовательские ML-инсайты, чтобы предлагать неочевидные конфигурации.
- Устойчивость к реальным сбоям. Инфраструктурные ошибки, ограничения по GPU, out-of-memory, нестабильное обучение — все это не должно каждый раз возвращать процесс человеку.
Для этого REA использует механизм hibernate-and-wake, двухконтурный движок генерации гипотез и трехфазную схему планирования: Validation → Combination → Exploitation. Звучит строго, но по сути логика понятная: сначала проверить идеи, потом объединить сильные, затем выжать максимум из лучших кандидатов в рамках согласованного бюджета.
Как агент ведет многодневный workflow
Важный момент: сложная оптимизация ML-модели — это не одна задача и не один prompt. Это цепочка зависимых действий, растянутая во времени. Иногда очень растянутая. Поэтому REA проектировался не как чат-ассистент, а как система, способная планировать, ждать, возвращаться, пересматривать решения и двигаться дальше.
1. Долгая автономная работа без постоянного надзора
Обычный AI-ассистент живет в короткой сессии. REA — нет. Когда агент запускает training job, он переводит процесс ожидания в фоновый режим, «засыпает», а затем автоматически «просыпается», когда задача завершается. Это и есть модель hibernate-and-wake.
На практике такой подход позволяет экономить ресурсы и не держать активный контекст там, где ничего не происходит. А когда результаты готовы, агент продолжает работу с того места, где остановился. Без ручного пинка. Ну, в идеале — совсем без него.
Внутри Meta REA построен на фреймворке Confucius, рассчитанном на сложные многошаговые сценарии рассуждения. Он дает доступ к генерации кода, SDK для интеграции с внутренними системами и связку с инфраструктурой: планировщиками задач, трекингом экспериментов и инструментами навигации по codebase.
2. Генерация гипотез, которые не выглядят банально
Слабая гипотеза — слабый эксперимент. Тут без сюрпризов. Поэтому REA опирается сразу на два источника знаний:
- базу исторических инсайтов — curated-репозиторий прошлых экспериментов, где можно увидеть, что уже срабатывало, а что нет;
- ML Research Agent — исследовательский компонент, который анализирует baseline-конфигурации и предлагает новые стратегии оптимизации.
Смысл в том, что агент не просто копирует прошлые удачи и не просто фантазирует на тему новых идей. Он совмещает оба подхода. Именно на стыке исторической памяти и исследовательского поиска появляются наиболее сильные комбинации. Кстати, в корпоративных AI-системах это очень похоже на то, как работают агентная память и RAG: знания не висят в воздухе, а становятся рабочим контекстом для следующего решения.
3. Работа в условиях ограничений, а не в лабораторном вакууме
Реальная инженерия редко бывает стерильной. GPU-бюджет ограничен. Джобы падают. Логи шумят. Где-то вылезает OOM, где-то обучение «взрывается», где-то инфраструктура просто решила, что сегодня не ее день. И вот тут проверяется, насколько агент вообще пригоден для production.
Перед запуском REA формирует подробный план исследования, оценивает стоимость вычислений и согласует ее с инженером. Обычно план разбит на три этапа:
- Validation. Отдельные гипотезы проверяются параллельно, чтобы быстро понять базовый потенциал каждой.
- Combination. Перспективные идеи объединяются — ищутся синергии, а не просто локальные улучшения.
- Exploitation. Лучшие кандидаты исследуются максимально плотно, чтобы получить наилучший результат в пределах утвержденного compute-бюджета.
Если что-то идет не так, REA не сразу зовет человека. Он сверяется с runbook типовых сбоев, отбрасывает явно неудачные jobs, пытается локализовать инфраструктурные проблемы и корректирует план в рамках заданных guardrails. Это уже не просто автоматизация по кнопке — это поведение, близкое к тому, что сегодня ждут от зрелых мультиагентных систем и enterprise AI-платформ.
При этом ограничения жесткие. Агент работает только внутри codebase рекламных ranking-моделей Meta, получает явно заданные права доступа и не может бесконтрольно расходовать ресурсы: бюджеты подтверждаются заранее, а при достижении лимитов запуск останавливается или ставится на паузу.
Архитектура REA: Planner, Executor и общая база знаний
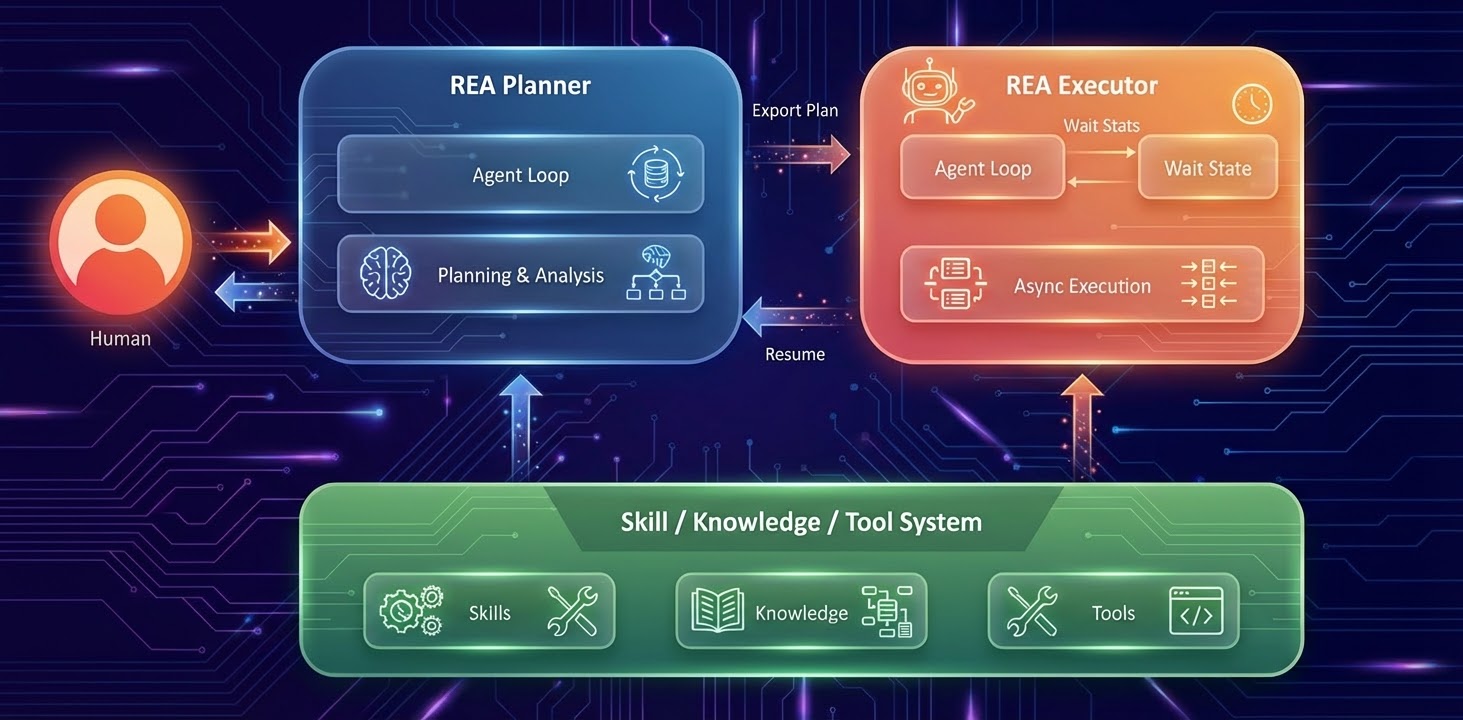
Архитектурно система состоит из двух основных компонентов: REA Planner и REA Executor. Их поддерживает общая платформа навыков, знаний и инструментов — именно она дает доступ к ML-функциям, истории экспериментов и внутренней инфраструктуре Meta.
Planner отвечает за формирование плана эксперимента. Инженер вместе с генератором гипотез определяет, что именно стоит проверить, в какой последовательности и с каким бюджетом. Затем эстафету принимает Executor, который уже ведет асинхронное выполнение: запускает jobs, уходит в wait state, возвращается к результатам, анализирует исходы и двигает цикл дальше.
Отдельно важен контур накопления знаний. По мере завершения экспериментов специальный logger записывает метрики, конфигурации и результаты в централизованную базу инсайтов. Эта память постепенно усиливает систему: следующие гипотезы строятся уже не «с нуля», а с учетом накопленного опыта. И да, именно такие механизмы особенно важны там, где встает вопрос о надежности, воспроизводимости и AI compliance и соответствии требованиям.
Устойчивость тоже распределена по всей архитектуре. Executor обрабатывает сбои и сигналы нестабильности, Planner получает обратно уже не сырые прерывания, а практически полезный результат: что сработало, что не сработало и что делать дальше. Мелочь? Нет, это как раз то, что отличает игрушечный агент от рабочего.
Что получилось на практике
До 2x по точности моделей
В первой production-валидации на шести моделях итерации под управлением REA дали в среднем двукратный прирост точности относительно baseline-подходов. Для рекламного ранжирования это не просто красивая цифра в презентации: улучшения напрямую влияют и на результаты рекламодателей, и на качество пользовательского опыта.
До 5x по инженерной продуктивности
Не менее заметен эффект на стороне команд. REA автоматизирует рутинную механику ML-экспериментов, а инженеры могут сосредоточиться на том, что действительно требует человеческой головы: выборе направления, архитектурных решениях, оценке рисков, приоритизации.
Первые пользователи системы увеличили число предложений по улучшению моделей с одного до пяти за тот же промежуток времени. А работа, которая раньше требовала двух инженеров на одну модель, теперь выполнялась тремя инженерами сразу для восьми моделей. Цифры, прямо скажем, говорят сами за себя.
Что это меняет в ML-инженерии
REA показывает более широкий сдвиг: AI-агенты начинают брать на себя не отдельные микрозадачи, а целые рабочие контуры. Инженер в такой схеме не исчезает — и вряд ли исчезнет, если честно, — но его роль меняется. Меньше ручного перебора, больше стратегического контроля. Меньше возни с рутиной, больше работы с направлением исследований.
Meta подчеркивает, что конфиденциальность, безопасность и governance остаются критически важными. И это логично: чем автономнее агент, тем выше требования к контролю, доступам, трассируемости решений и общей безопасности AI-агентов. Дальше компания планирует развивать специализированные модели для генерации гипотез, расширять аналитические инструменты и переносить подход на другие домены.
В общем, история здесь не только про рекламное ранжирование. Она про то, как автономные AI-агенты постепенно становятся рабочим слоем современной инженерии. Не в теории — в проде. А это, согласитесь, уже совсем другой разговор.
Благодарности
Ashwin Kumar, Harpal Bassali, Shashank Ankit, Deepak Chandra, Chaorong Chen, Wenlin Chen, Vitor Cid, Peter Chu, Xiaoyu Deng, Jingyi Guan, Junhua Gu, Liquan Huang, Qinjin Jia, Santanu Kolay, Jakob Moberg, Shweta Memane, Jp Owed, Sandeep Pandey, Vijay Pappu, Shyam Rajaram, Ben Schulte, Jags Somadder, Matt Steiner, Ritwik Tewari, Hangjun Xu, Zhaodong Wang, Fan Yang, Xin Zhao, Zoe Zu