
Масштабирование Managed Agents: как отделение «мозга» от «рук» ускоряет AI-агентов и упрощает архитектуру
Масштабирование Managed Agents: отделение «мозга» от «рук»
Любой harness рано или поздно стареет: в нём зашиты предположения о том, чего модель пока не умеет. Как только модели становятся сильнее, эти допущения начинают мешать. Managed Agents — это hosted-сервис Anthropic для агентных сценариев с длинным горизонтом, построенный вокруг интерфейсов, которые переживают смену реализаций. И это, честно говоря, куда важнее, чем кажется на первый взгляд.
Начать работу с Claude Managed Agents можно через их документацию.
В инженерных материалах Anthropic давно тянется одна и та же нить: как строить действительно полезных агентов и как проектировать harness для длительных, многошаговых задач. Смысл простой, но колкий: harness — это не магия, а набор инженерных костылей и правил, которые компенсируют текущие ограничения модели. Сегодня они помогают. Завтра — уже путаются под ногами.
Если смотреть шире, это ровно та проблема, с которой сталкивается почти любая команда, занимающаяся разработкой AI-агентов и автоматизацией: модель меняется быстрее, чем инфраструктура вокруг неё. И вот тут начинается самое интересное.
Один показательный случай Anthropic уже описывала раньше. Claude Sonnet 4.5 иногда завершал задачу слишком рано, когда «чувствовал», что окно контекста подходит к пределу. Это поведение неофициально называли context anxiety — тревожностью из-за контекста. Проблему закрыли сбросами контекста внутри harness. Работало. Но потом тот же самый подход попробовали с Claude Opus 4.5 — и выяснилось, что симптом исчез. Всё, что вчера было лечением, сегодня стало лишним грузом. Ну да, бывает.
Именно поэтому Anthropic исходит из довольно трезвой мысли: harness будет меняться снова и снова. Отсюда и Managed Agents — сервис в Claude Platform, который запускает long-horizon AI-агентов от имени пользователя, но опирается не на хрупкую конкретную реализацию, а на небольшой набор устойчивых интерфейсов.
По сути, команда решала старую, почти классическую вычислительную задачу: как проектировать систему под «ещё не придуманные программы». Когда-то операционные системы справились с этим, скрыв железо за абстракциями вроде process и file. Благодаря этому read() остаётся read(), независимо от того, идёт ли речь о древнем диске или современном SSD. Верхний слой стабилен, нижний — меняется сколько угодно. Удобно. И, если честно, очень по-взрослому.
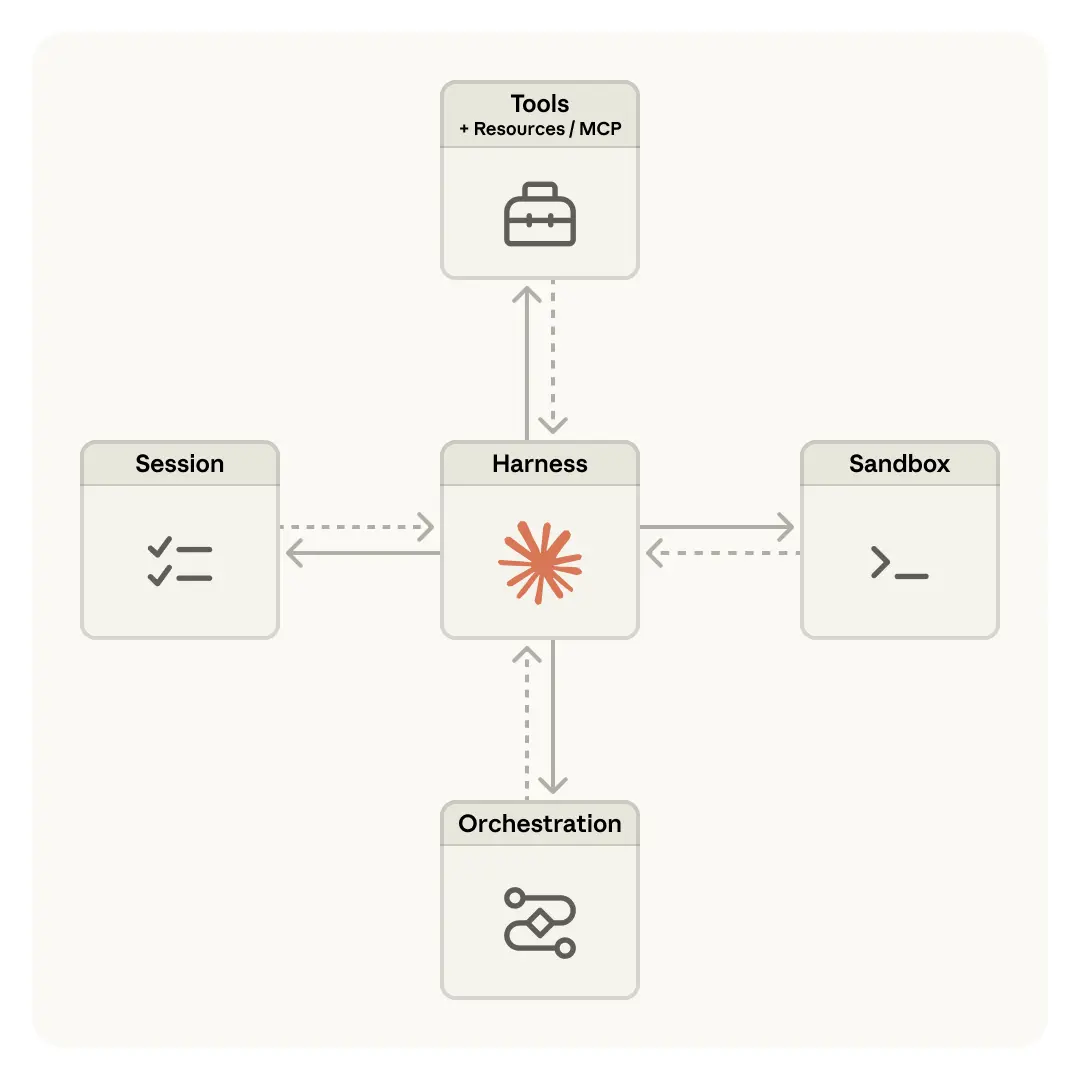
Managed Agents устроены похожим образом. В Anthropic виртуализировали ключевые части агента: session — append-only журнал всего, что произошло; harness — цикл, который вызывает Claude и маршрутизирует tool calls; sandbox — среду, где модель может запускать код и править файлы. Благодаря этому можно менять реализацию каждого слоя отдельно, не разваливая всё остальное. Это уже не просто удобная инженерия, а полноценная архитектура AI-агентов, рассчитанная на эволюцию моделей, инструментов и требований безопасности.
Не заводите «питомца»
Сначала всё было устроено проще: session, harness и sandbox жили внутри одного контейнера. У такого варианта, конечно, были плюсы. Файлы редактировались через прямые системные вызовы, не нужно было продумывать межсервисные границы, да и в целом схема выглядела аккуратно — почти слишком аккуратно.
Но затем вылезла старая инфраструктурная болячка: контейнер превратился в «питомца». В модели pets vs cattle питомец — это уникальный экземпляр, за которым нужен ручной уход, который жалко потерять и который все знают по имени. Cattle — наоборот, взаимозаменяемые узлы: один умер, подняли другой и пошли дальше. У Anthropic контейнер оказался именно питомцем. Если он падал, терялась session. Если зависал, его приходилось буквально выхаживать вручную.
А это уже неприятно. И дорого по времени.
Отладка зависших или неотвечающих session превращалась в угадайку. Единственное окно в систему — поток событий WebSocket — не позволяло понять, где именно всё сломалось: в harness, в event stream или в самом контейнере. Снаружи эти сбои выглядели одинаково. Чтобы докопаться до причины, инженеру приходилось заходить в shell внутри контейнера. И вот тут начиналось неловкое: контейнер нередко содержал ещё и пользовательские данные. То есть формально отладка была возможна, а по-человечески — не очень.
Была и вторая проблема. Harness исходно предполагал, что всё, с чем работает Claude, находится рядом — в том же контейнере. Пока инфраструктура замкнута на себя, это терпимо. Но как только клиенты захотели подключать агента к собственному VPC, конструкция заскрипела. Приходилось либо настраивать network peering между сетями клиента и Anthropic, либо вообще запускать harness в инфраструктуре заказчика. Иными словами, допущение, которое казалось безобидным, внезапно стало архитектурным ограничением. Классика.
Отделить мозг от рук
В итоге Anthropic пришла к более чистой схеме: отделить «мозг» — Claude и harness — от «рук», то есть sandbox и инструментов, которые реально совершают действия, а заодно и от session, где хранится журнал событий. Каждый из этих элементов стал самостоятельным интерфейсом с минимальным числом предположений о соседях. Если один слой ломается, остальные не обязаны падать следом. Уже лучше. Намного.
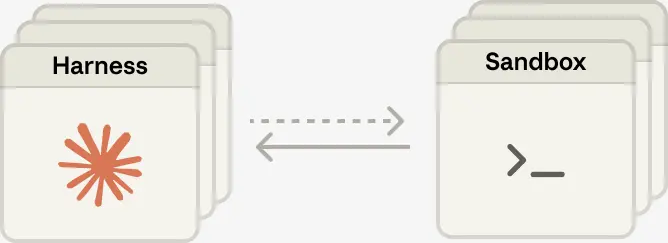
Harness уходит из контейнера. Как только «мозг» перестал жить внутри контейнера, sandbox начал вызываться так же, как любой другой инструмент: execute(name, input) → string. Контейнер стал тем самым cattle. Если он завершался с ошибкой, harness воспринимал это как ошибку tool call и возвращал её Claude. Если модель решала повторить попытку, новый контейнер поднимался по стандартной процедуре: provision({resources}). Без ручной реанимации. Наконец-то.
Сбой harness больше не катастрофа. Сам harness тоже стал взаимозаменяемым. Поскольку session хранится отдельно, в экземпляре harness нет ничего такого, что обязано пережить crash. Если один процесс падает, другой можно поднять через wake(sessionId), затем вызвать getSession(id), восстановить журнал и продолжить с нужного места. Во время agent loop события пишутся через emitEvent(id, event), так что история остаётся целой. Не идеально волшебно, но очень практично.

Граница безопасности становится реальной, а не декоративной. В старой связанной архитектуре любой недоверенный код, который генерировал Claude, выполнялся в том же контейнере, где лежали credentials. А значит, для prompt injection задача была почти комично прямолинейной: заставить модель прочитать собственное окружение. Получив токены, атакующий мог создавать новые session и масштабировать злоупотребление дальше. Да, можно ограничивать scope токенов, но это всё равно опирается на предположение, что модель «не додумается» сделать что-то опасное с ограниченными правами. Ставка так себе.
Структурное решение оказалось жёстче и надёжнее: токены вообще не должны быть доступны из sandbox, где исполняется код, сгенерированный моделью. Это уже не косметика, а нормальная безопасность AI-агентов.
Для этого Anthropic использует два паттерна. Первый — привязка авторизации к ресурсу. Второй — хранение секретов во внешнем vault, вне sandbox. Например, для Git применяется access token конкретного репозитория: он используется при инициализации sandbox для клонирования repo и настройки локального remote. После этого команды push и pull работают внутри sandbox без прямого доступа агента к самому токену. Для custom tools поддерживается MCP, а OAuth-токены лежат в защищённом vault. Claude вызывает MCP tools через выделенный proxy: тот принимает токен session, достаёт нужные credentials из vault и уже сам обращается к внешнему сервису. Harness при этом секретов не видит вообще. И это, пожалуй, правильный уровень паранойи.
Session — это не окно контекста Claude
Длинные задачи почти неизбежно упираются в размер контекстного окна. Обычные способы обхода этой проблемы — compaction, memory tools, trimming — всегда требуют принять необратимое решение: что сохранить, а что выбросить. Иногда это работает отлично. Иногда — до первого странного сбоя, который потом никто не может воспроизвести.
Anthropic уже писала о context engineering: Claude может сохранять summary окна контекста, записывать важные данные в файлы, а harness — выборочно удалять старые tool outputs или блоки рассуждений. Но проблема в том, что заранее невозможно точно знать, какие токены понадобятся позже. Если сообщения были преобразованы во время compaction, а исходные данные больше нигде не лежат, вернуть их уже нельзя. Всё. Поезд ушёл.
В более ранних исследованиях предлагался другой подход: хранить контекст как объект вне окна модели — например, в REPL, куда LLM обращается программно, фильтруя или нарезая данные по мере необходимости. В Managed Agents ту же роль играет session. Это не просто лог, а внешний объект контекста, который живёт вне текущего окна Claude и доступен для повторного анализа.
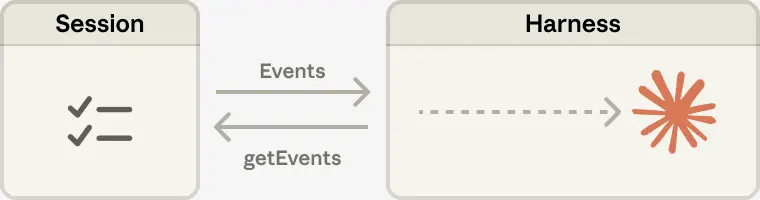
Интерфейс getEvents() позволяет «мозгу» исследовать журнал событий по позиционным срезам. Можно продолжить чтение с того места, где остановились, отмотать назад перед важным действием, перечитать предысторию конкретного шага — словом, работать с контекстом не как с одноразовой салфеткой, а как с полноценным источником состояния.
При этом события, извлечённые из session, можно дополнительно преобразовывать в harness перед тем, как отправлять их в окно контекста Claude. Эти преобразования могут быть любыми: от оптимизации prompt cache hit rate до сложных стратегий context engineering и агентной памяти и RAG. Anthropic сознательно разделила две задачи: надёжное, восстанавливаемое хранение контекста — в session; произвольное управление тем, как этот контекст подаётся модели, — в harness. Потому что заранее угадать, какой именно подход понадобится следующим поколениям моделей, ну… вряд ли возможно.
Много мозгов, много рук
Много мозгов. Отделение «мозга» от «рук» решило одну из первых и самых практичных клиентских претензий. Когда команды хотели, чтобы Claude работал с ресурсами внутри их VPC, старая схема фактически вынуждала настраивать peering между сетью клиента и сетью Anthropic. После выноса harness из контейнера это ограничение исчезло.
Но выигрыш оказался не только архитектурным, а ещё и вполне измеримым. Когда «мозг» сидел внутри контейнера, каждый новый агент требовал собственный контейнер. А значит, inference не мог начаться, пока контейнер не был provisioned. Каждая session заранее платила полную цену за инициализацию: клонирование репозитория, запуск процессов, получение ожидающих событий. Даже если sandbox в итоге вообще не понадобился. Немного абсурдно, если вдуматься.
Эта задержка отражается в метрике time-to-first-token, или TTFT, — времени между принятием задачи и выдачей первого токена ответа. Именно её пользователь ощущает кожей, без всяких графиков.
После разделения архитектуры контейнеры поднимаются только по требованию, через tool call execute(name, input) → string. Если session не нужен sandbox прямо сейчас, она не ждёт его инициализации. Inference стартует сразу после того, как orchestration layer забирает ожидающие события из журнала session. Результат — p50 TTFT снизился примерно на 60%, а p95 — более чем на 90%. Масштабирование до множества «мозгов» свелось к запуску набора stateless harness и подключению «рук» только тогда, когда это действительно нужно.
Много рук. Следующий шаг — дать каждому «мозгу» доступ не к одной, а ко многим средам выполнения. На практике это означает, что Claude должен понимать, с какими execution environments он имеет дело, и решать, куда отправить работу. Это уже когнитивно сложнее, чем один shell и одна песочница. Ранние модели с таким справлялись плохо, поэтому изначально всё и держали в одном контейнере.
Но по мере роста возможностей моделей ограничением стал уже сам single-container approach. Если контейнер выходил из строя, терялось состояние всех «рук», с которыми работал агент. После разделения каждая «рука» стала обычным инструментом с единым интерфейсом: execute(name, input) → string. На вход — имя и параметры, на выход — строковый результат. За этим интерфейсом может стоять что угодно: custom tools, MCP servers, собственные инструменты Anthropic. Harness не обязан знать, является ли «рука» контейнером, телефоном или, скажем, эмулятором Pokémon. Звучит чуть дико, но именно в этом и сила абстракции.
А ещё такая схема естественно ведёт к мультиагентным системам: «мозги» не привязаны жёстко к конкретным «рукам», поэтому могут передавать инструменты друг другу, делить окружения и координировать работу без лишней сцепки.
Что это значит на практике
Если убрать красивую метафору про мозг и руки, останется очень приземлённый инженерный вывод: устойчивые интерфейсы важнее конкретных реализаций. Anthropic строит не «идеальный harness на все времена», а мета-слой, который допускает разные harness, sandboxes и способы управления контекстом. Сегодня это один набор решений. Завтра — другой. Система не должна ломаться от того, что модель стала умнее.
В этом смысле Managed Agents — не просто продуктовая функция, а довольно зрелая ставка на будущее агентных систем. Claude Code может быть отличным harness для одних задач. Узкоспециализированные task-specific harness — для других. Managed Agents не навязывает один-единственный путь, а создаёт каркас, в который можно встроить разные варианты по мере развития моделей и требований бизнеса.
И да, это особенно важно для enterprise-сценариев, где нужны не только скорость и гибкость, но и наблюдаемость, отказоустойчивость, контроль доступа и AI compliance и соответствие требованиям. Потому что в корпоративной среде «оно вроде работает» — не архитектура. Это временная удача.
Итог простой. Anthropic спроектировала систему с чёткими интерфейсами вокруг Claude: для хранения состояния, выполнения вычислений, масштабирования на множество «мозгов» и множество «рук». Но при этом команда сознательно не зафиксировала, сколько именно этих «мозгов» и «рук» понадобится в будущем и где они будут находиться. В этом, собственно, и весь смысл хорошей платформы для AI-агентов: она оставляет пространство для следующего шага, даже если этот шаг пока никто толком не видит.
Благодарности
Материал подготовили Lance Martin, Gabe Cemaj и Michael Cohen. Отдельная благодарность команде Agents API и Jake Eaton за вклад в эту работу.
Подпишитесь на рассылку для разработчиков
Обновления продуктов, практические руководства, новости сообщества и другие полезные материалы. Письма приходят раз в месяц — без лишнего шума, по делу.
Если хотите получать ежемесячную рассылку для разработчиков, укажите свой email-адрес. Отписаться можно в любой момент.